Blitz-SLAM
对论文 Blitz-SLAM: A Semantic SLAM in Dynamic Environments (Pattern Recognition 2022) 的阅读总结。Blitz-SLAM 使用 BlitzNet 提取目标检测框和掩码,用于剔除动态物体,实现语义 SLAM。
论文情况
- 标题:Blitz-SLAM: A Semantic SLAM in Dynamic Environments
- 作者:Yingchun Fan, Qichi Zhang, Yuliang Tang, Shaofen Liu, Hong Han
- 期刊:Pattern Recognition 2022
- 源码:未开源
1 Introduction
现存的多数 SLAM:
- 假设:静态的环境。
- 问题:静态环境假设提取的特征点应出现在静态物体上,若场景中存在动态物体,则特征点可能会提取在这些物体上。
- 解决:使用 RANSAC 在静态或低动态环境中去除匹配失败的点。然而无法保证在高动态环境下也能去除匹配失败点。
SLAM + Deep Learning:
- 动机:目标检测和目标分割的成熟。
- 方法:将预先定义的运动物体(如人、汽车等)的语义信息与空间几何信息相结合,去除运动物体的负面影响。
- 问题:目前的语义分割方法所提供的物体原始掩码不能完全覆盖移动的物体。
本文研究:
- 成果:提出工作在室内动态环境下的语义 SLAM —— Blitz-SLAM。
- 特点:
- 使用 ORB-SLAM2 的前端移除动态物体。
- 使用 BlitzNet[1] 获取物体的语义信息。BlitzNet 可以获取物体的 bounding box 和 mask。运动物体的边界框将图像分为动态区域和静态区域;使用深度图的几何信息矫正掩码,使其能更完整的覆盖动态物体,且能将局部点云的噪声块移除。
本文贡献:
- 提出通过结合原始掩码和物体深度信息的掩码矫正方法;
- 提出在构建点云地图时,约束运动物体产生的噪声块的方法;
- 提出解决运动物体多次出现在全局点云地图中的方法。
2 System Description
2.1 Overview of Blitz-SLAM
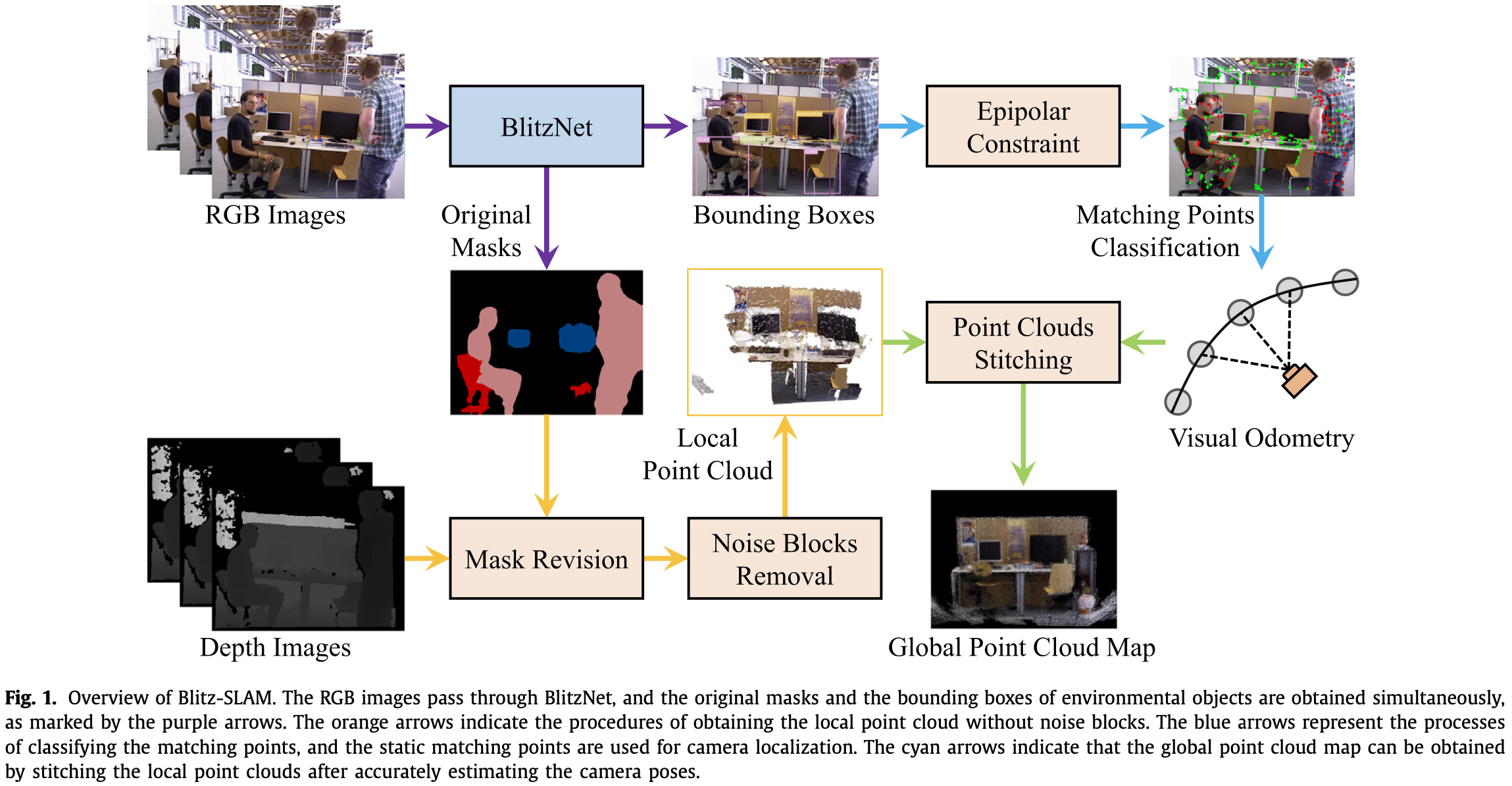
RGB 图像先被输入 BlitzNet 中,同时获取到环境中物体的边界框和掩码。
- BlitzNet 使用 ResNet-50 作为 backbone,并在 PASCAL VOC 数据集上得到训练,能够分割和检测 20 个类别(如人、家具)的物体。
根据环境中物体的状态,可以分为三类:
- 运动中物体(moving objects):如行走中的人。物体不仅直接影响相机位姿估计,还会影响建图。
- 静态物体(static objects):如桌子、镜子等。主要以静态形式出现在环境中,并且不会被频繁移动。
- 可运动物体(movable objects):如椅子、书等。可运动、也可静止的物体。
由于 BlitzNet 获得的原始物体掩码不完整,因此物体所在区域的深度信息作用于原始掩码获取矫正掩码,使得能完全覆盖物体区域。如 Fig.1 中黄色箭头,通过移除动态物体产生的噪声块,可以得到局部点云。
在处理相机定位时,通过 moving objects 的边界框可以讲图像分为环境区域和潜在动态区域。利用环境区域的匹配点构造对极约束,分类潜在动态区域内的动态和静态匹配点。之后,静态匹配点用于相机定位,流程如 Fig.1 中蓝色箭头。
Fig.1 中青色箭头表示构建全局点云地图,本质是将每组关键帧对应的局部点云合并(非简单加和,只是一种抽象表达):
表示局部点云, 表示全局点云,旋转 和平移 由相机在世界坐标系下的位姿决定。取第一组关键帧的相机坐标系为世界坐标系。
全局点云地图的准确性取决于:
- 相机定位精度;
- 局部点云中噪声块(动态物体)的去除;
- 相机轨迹的完整性。
2.2 Depth Region Segmentation
由于深度相机的缺陷,深度图像的一些区域会丢失深度。当物体表面非常光滑时,物体的深度信息也会严重丢失。
基于假设 [2]:场景中的物体(尤其人工物体)很大程度上是凸的(convex),因此在深度图的非连续区域放置边缘点。深度图分割方法则如下:
-
使用 的窗口遍历深度图,用 (2) 式记录下此窗口的深度,其中 表示像素坐标:
-
边缘点可以通过 (3) 式获取,其中 表示阈值, 表示边缘点集合:
2.3 Removal of Depth Unstable Regions
深度相机的精度随物体距相机距离的增大而减小。为观测点云上深度不稳定区域的影响,使用 TUM 数据集中的一些 RGB 和 深度图,生成的局部点云,如 Fig.2。
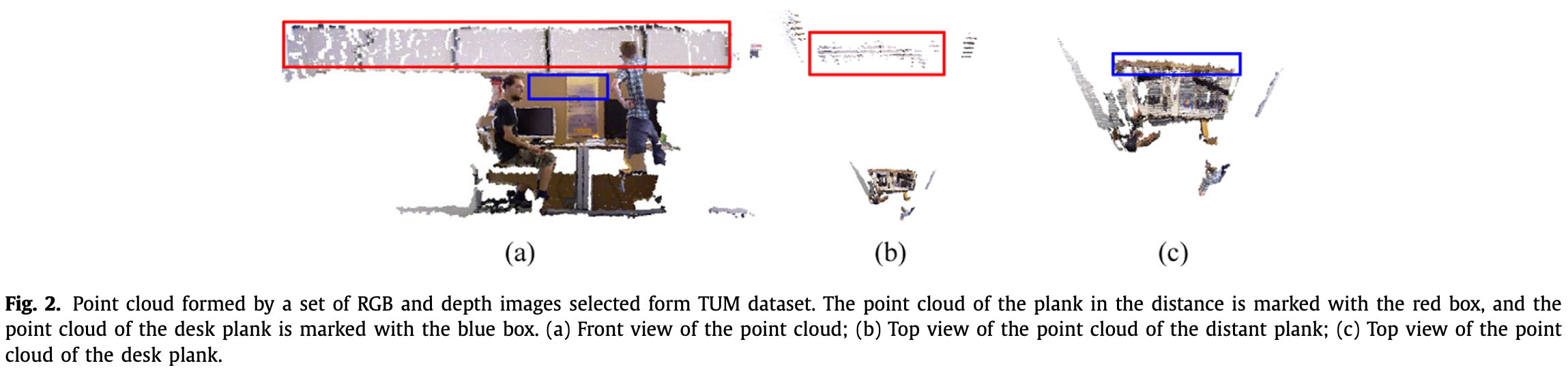
- 从正面看,远处木板的点云比桌面的点云占据更大的区域。
- 从上看,远处木板的点云具有严重的层次性,而桌面的点云则较为紧凑。
- 当多个局部点云合并时,远处平板的分层现象会更加严重,直接影响全局点云图的视觉效果。
因此,为了点云地图的质量,需要去除深度不稳定区域:当深度图中点的深度值大于 时,设置点的深度值为 。
2.4 Depth Mask
BlitzNet 获取的原始掩码存在两个问题:
- 掩码无法完全覆盖物体;
- 被掩码覆盖的物体可能包含环境和其他物体的信息。
因此直接使用原始掩码构建的语义点云地图存在两个问题:
- moving objects 的信息会渗入环境,产生噪声块;
- 如果掩码超出了 static objects 的区域,部分语义信息会被映射到其他环境点。
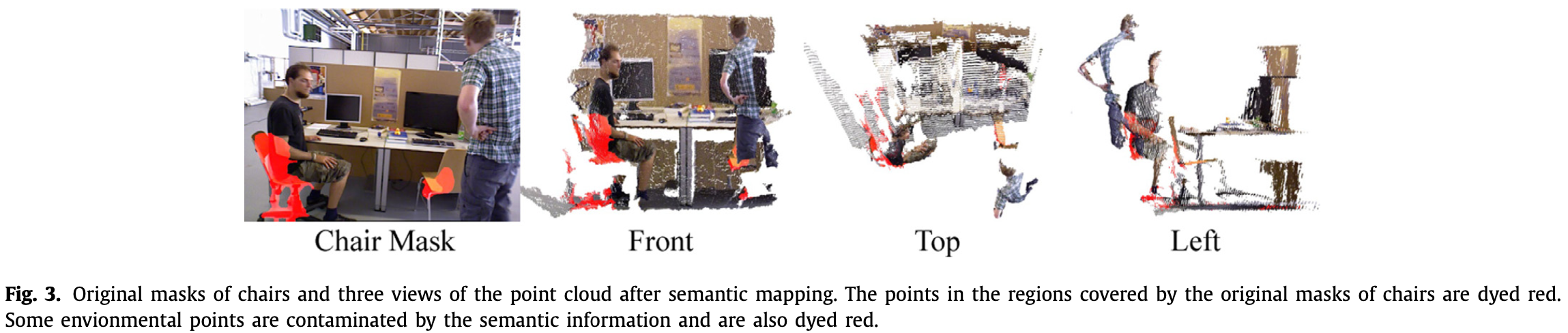
如 Fig.3,转椅的原始掩码(红色)覆盖了部分坐着的人,而右边(橙色)则没有完全覆盖椅子。将两把椅子原始掩码提供的语义信息映射到当前点云上,可以发现一些环境点也被染成了红色。
使用原始掩码 覆盖区域的深度信息改进掩码,得到深度掩码 :
-
首先,物体的原始源码用于给图像中的物体打标签,将所有的物体的记为 ;
-
然后,计数原始掩码 区域内的深度信息,移除深度值为 的点或 outliers,得到深度值集合 。用 (4) 式,找到深度图中和 有相同深度范围的像素:
和 为 的最大和最小值, 表示像素 的深度值, 表示和 有相同深度范围的区域。为提高系统鲁棒,扩展 区域的深度范围 ,其中 。
可能包含多个有相同深度范围的图像块 :
-
最后,构建语义约束来保存属于深度掩码 的图像块:
表示 中有 语义信息的像素的数量, 为 中总的像素数量, 为为阈值。
深度掩码获取算法如下:

矫正掩码 则为原始掩码和深度掩码的并集:
对 对处理:
- 如果 为 moving object,则需要移除被 覆盖的区域;
- 如果 为 static object,当构建语义点云图时,被 覆盖区域的语义信息需要被映射分配。
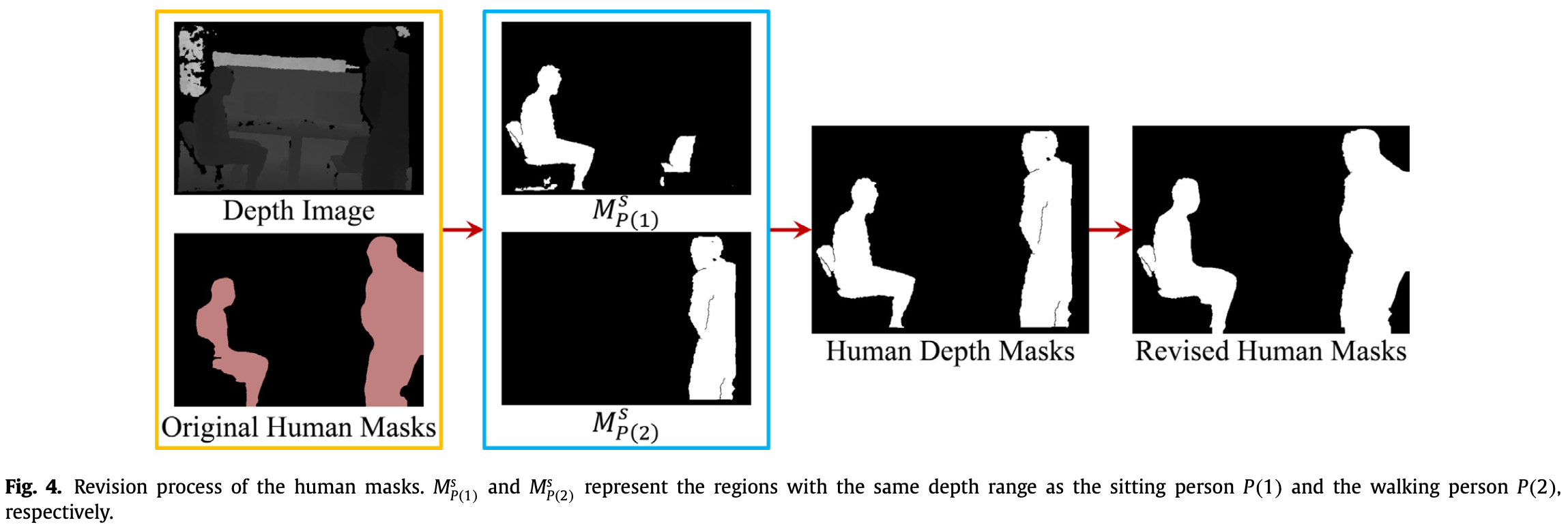
Fig.4 表示了掩码的修正过程:
- 输入(黄框)为两个人的原始掩码及对应的深度图,坐着的人标签为 ,站着的人为 ;
- 得到的同深度范围区域为 和 (蓝框),其中 包含多个图像块,通过 (6) 式去除多余图像块后,得到深度掩码 ;
- 最后,深度掩码与原始掩码融合得到矫正掩码。
2.5 Judgement of Interaction between Moving People and Movable Object
当人的矫正掩码和 movable object 的矫正掩码相交时,则:
其中 表示图像中的人, 表示图像中的 movable objects。 表示 moving objects 集合, 为 static objects 集合。
人和 movable objects 的相交判断算法如下:

Fig.5 表示了判断人和椅子是否相交:
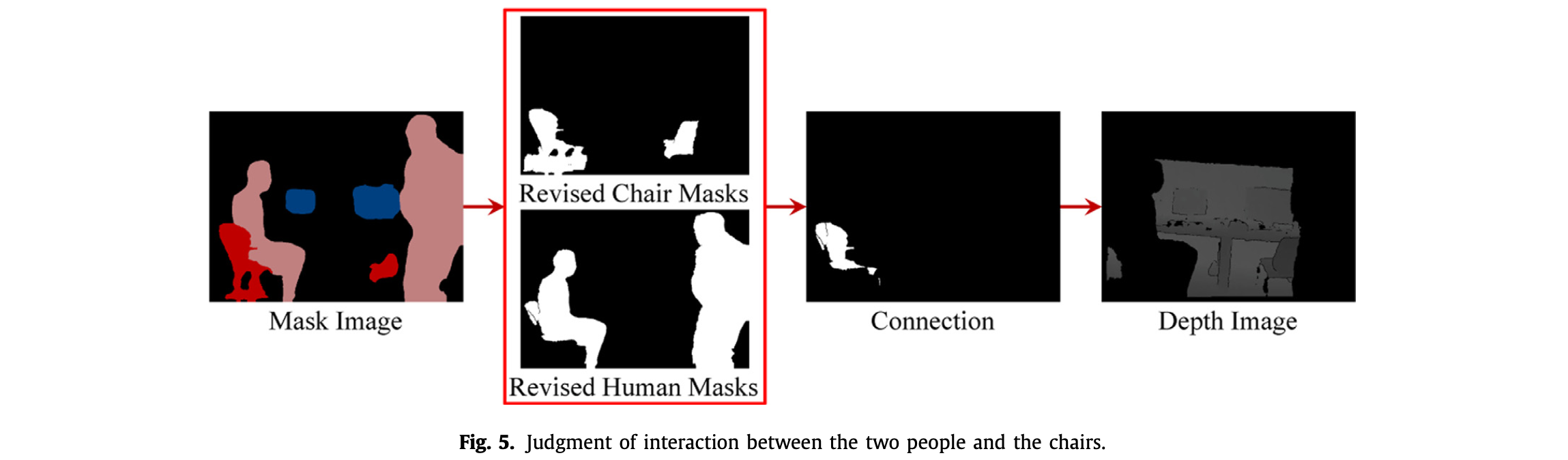
- 输入两个人和两把椅子的矫正掩码(红框),从左到右,两把椅子的标签为 和 ,人的标签为 和 。经过判断, 和 相交,则 变为 moving objects。

- 将被两个人和 的矫正掩码覆盖的区域的深度值设为 0,将 的语义信息映射到当前点云。如 Fig.6,moving objects 被有效去除, 的语义信息也没有污染其他环境点。
2.6 Removal of the Residual Information of Moving Objects
移除矫正掩码覆盖的区域后,moving object 的部分边界信息可能会遗留在环境中。这些残留边界形成的噪声块长而窄,因此需要进行去除。如 Fig.7 为边界信息去除的流程,输入为 RGB 图像以及移除被矫正掩码覆盖区域后的深度图像,输出为无噪声块的深度图:
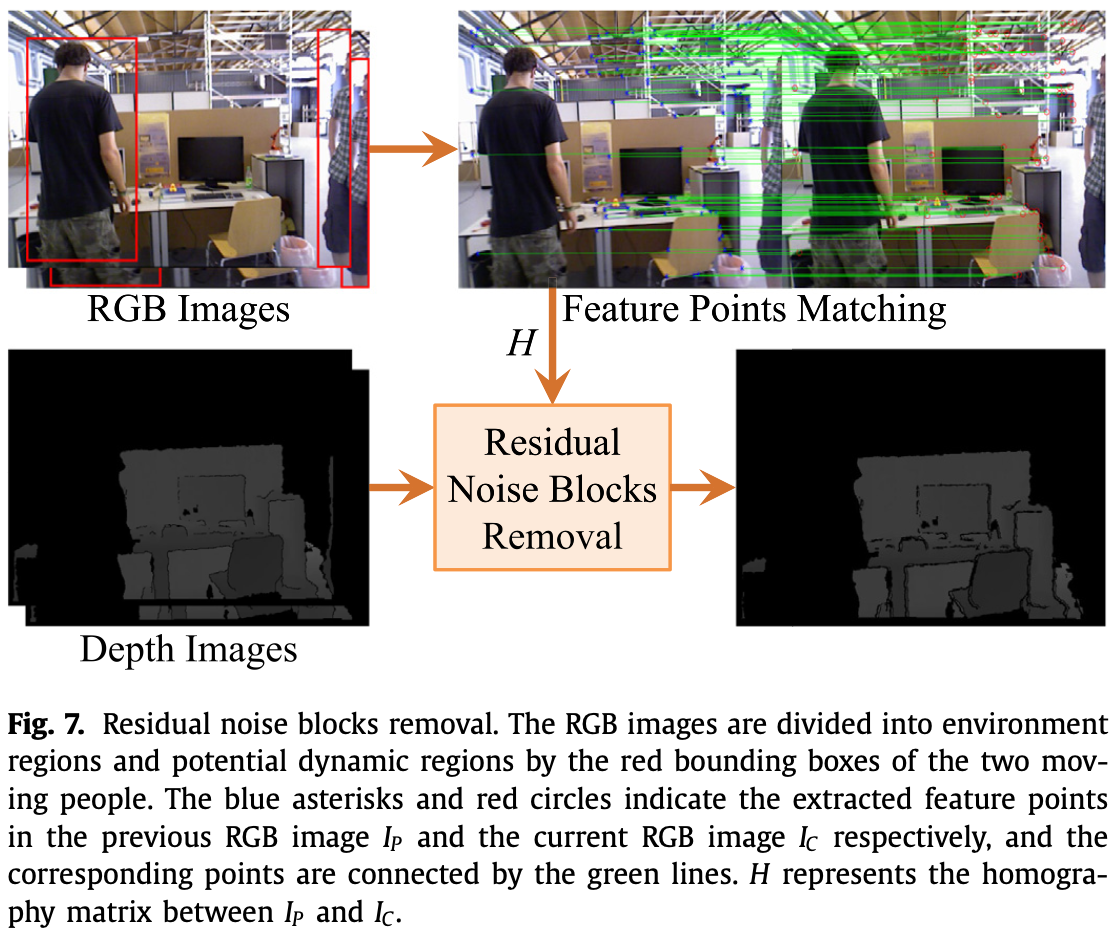
首先,从前一帧 和当前帧 的环境区域提取特征点。 和 之间的单应矩阵(homography matrix) 可以通过 RANSAC 和 LM 算法计算得到。
假设 为点在 的坐标, 为点在 的坐标,这些点为特征匹配点,而且可以得到 (9) 式(得到 在 的投影点):
相邻帧上残留边界位置的深度值通常相差较大,因此,噪声块可以通过以下 (10) 式的判断去除:
其中 和 表示 和 对应的深度图, 为阈值。
最后,通过形态学操作(morphological operations)移除深度图像上少于 1000 个像素的图像块,确保 moving objects 被完全移除。moving objects 的残留信息移除算法如 Algorithm 3:

Fig.8 则为一个点云去除噪声块前后的对比,噪声块被红色框标出:
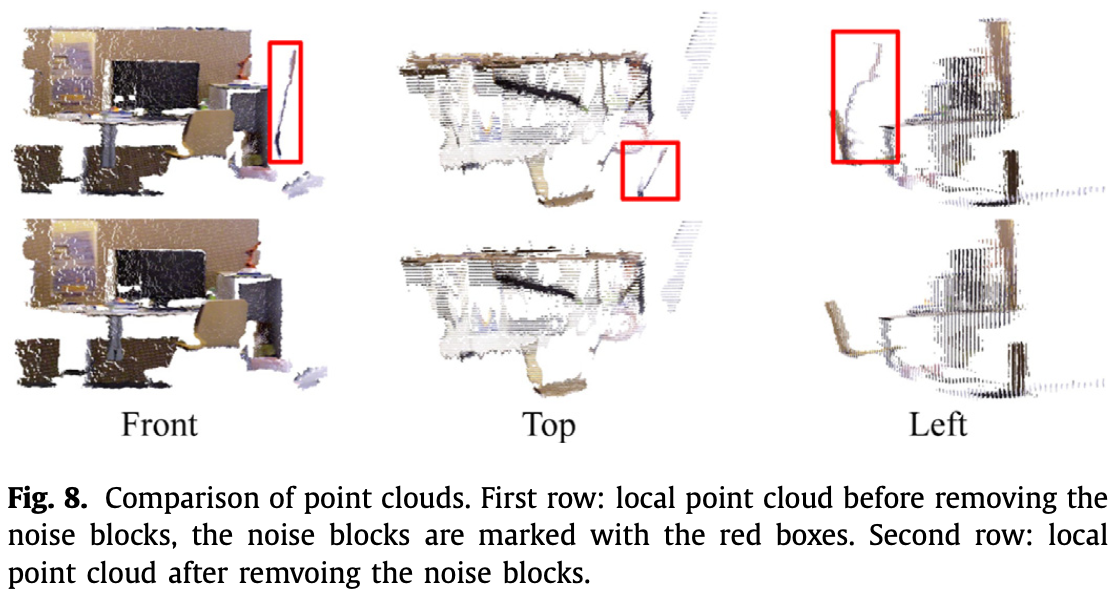
每次有人移动 movable objects,这些物体的位置相较之前会发生更改,如果无法处理这种情况,这些物体产生的冗余信息就会体现在全局点云地图上。文中采取了只保留这些物体的最近信息。

Fig.9 展示了两把椅子在 4 个阶段的状态变化,两把椅子需要被保留的信息为绿框中的内容:
- 初始阶段,椅子是 static object,信息被保留在全局地图中。
- 第二阶段,两个人进入图像并与椅子相交,椅子成为动态物体且不参与建图。此时,椅子在地图中的信息为第一个红框中的信息。
- 第三阶段,两个人离开图像,椅子变为静止,由于椅子的位置发生改变,第一阶段保留的椅子信息被删除,保留当前的信息。
- 最后阶段,两个人再次与椅子相交,则如第二阶段,信息不被保留,且地图中当前为第三阶段保留的椅子信息。
2.7 Location of the Static Matching Points
在获得前一帧 和当前帧 的两个静态匹配点集 和 ,从 到 的相机位姿可以通过求解一下最小二乘得到:
2.6 部分仅提取了静态区域的特征点,然而提取方法中部分区域被视为潜在动态区域( 和 ),没有被提取到特征。因此,此部分则讨论如何提取潜在动态区域的特征点。
首先,从 和 的环境区域提取匹配特征点,通过 RANSAC 算法求得两帧图像之间的基础矩阵(fundamental matrix)。
然后,在 和 的潜在动态区域提取匹配点集 和 。
之后,通过极线计算潜在动态匹配点之间的距离:
其中, 和 的值为:
潜在动态区域的匹配点的第 个特征点的状态,可以通过 (14) 式判断匹配点之间的距离获取:
其中 表示动态匹配点集, 表示静态匹配点集,。静态匹配点的定位算法如下:

3 Experimental Results
Baseline:ORB-SLAM2,Dyna-SLAM,DS-SLAM
Dataset:TUM RGB-D
相机的运动四种状态模式:
- halfsphere:相机沿着半球体的轨迹移动;
- rpy:相机绕固定轴旋转;
- static:相机固定在某个位置;
- xyz:相机沿着 x,y,z 轴移动。
八个图像数据序列:fr3/w/half,fr3/w/rpy,fr3/w/static,fr3/w/xyz,fr3/s/half,fr3/s/xyz,fr2/desk/p,fr2/xyz。其中 fr、s、w、p 表示 Freiburg(弗莱堡,德国地名)、sitting、walking、person,desk 序列为行走的人手持相机拍摄的数据。
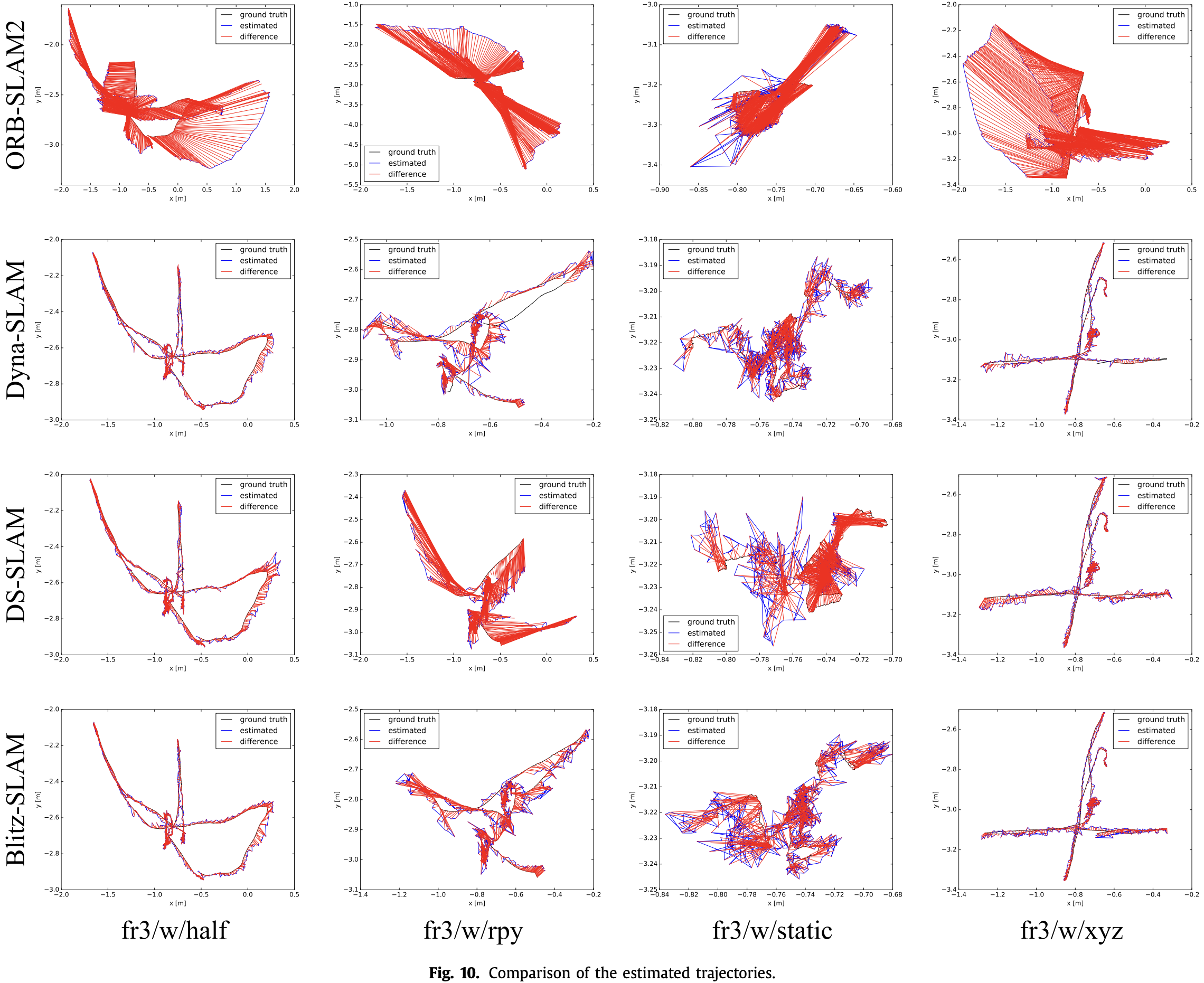
3.1 Evaluation of Camera Localization
- 定量测量:绝对轨迹误差(ATE)、相对位姿误差(RPE)。
设 表示估计的相机位姿, 表示 GT。全局轨迹连续性的 ATE,或时间步 时的 ATE 可以通过 (15) 计算:
其中 表示将估计轨迹与实际轨迹对齐的刚体变换。
RPE 测量了固定时间 下的局部轨迹精度,时间步 的 RPE 可以通过 (16) 式计算:
- 定量分析:RMSE(Root Mean Square Error)和 S.D.(Standard Deviation)。RMSE 测量观测值和真值的误差,S.D. 测量群体相对整体的偏差。
如 Table-1 至 Table-3 为定量分析结果,表中 improvements 的计算为:
其中 为 ORB-SLAM2 的测量结果, 为 Blitz-SLAM 的测量结果。
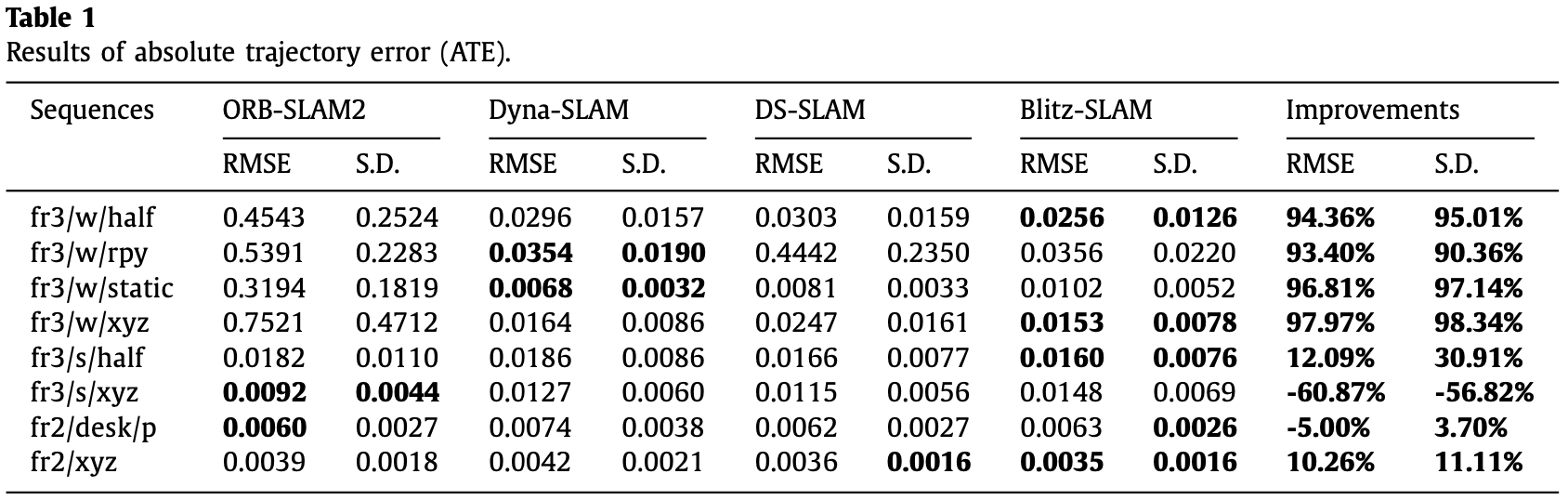
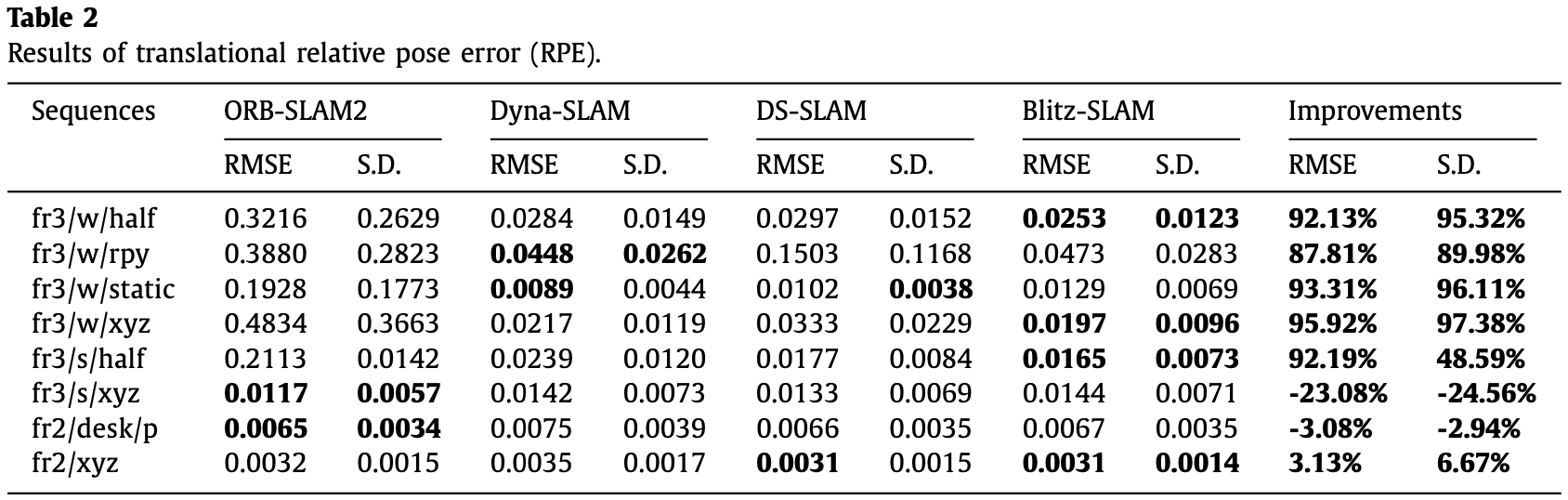
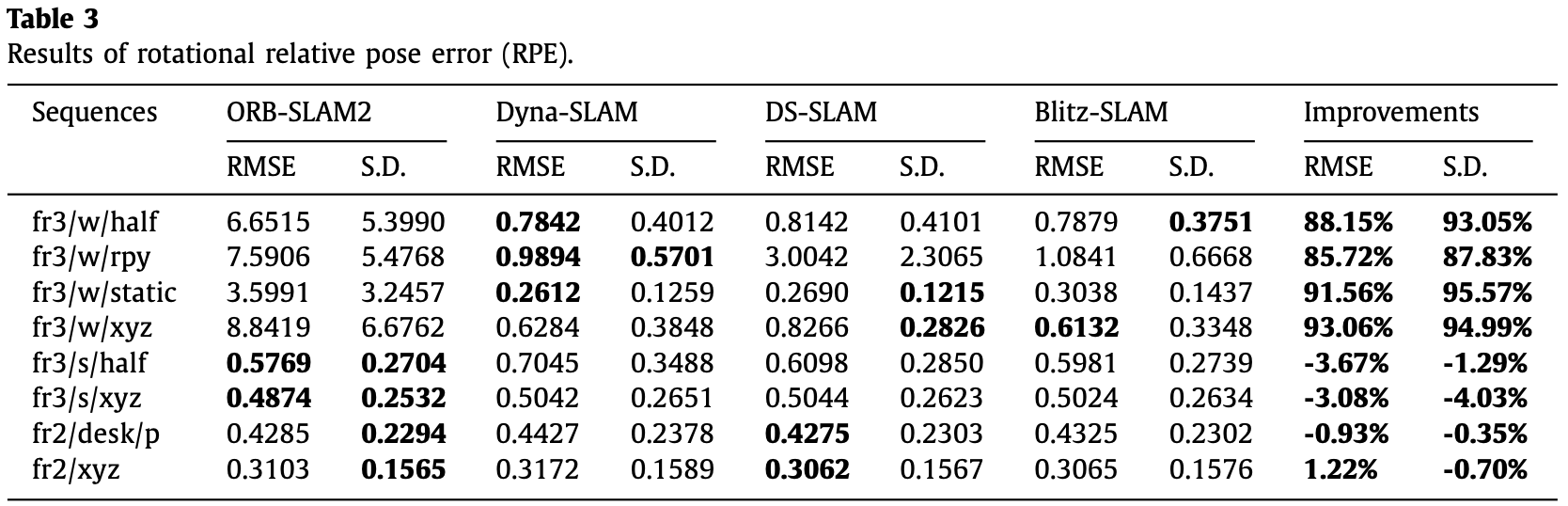
- 在高动态环境下能实现明显优于 ORB-SLAM2 的结果;
- 在低动态环境下取得的效果相比 ORB-SLAM2 基本无明显下降。
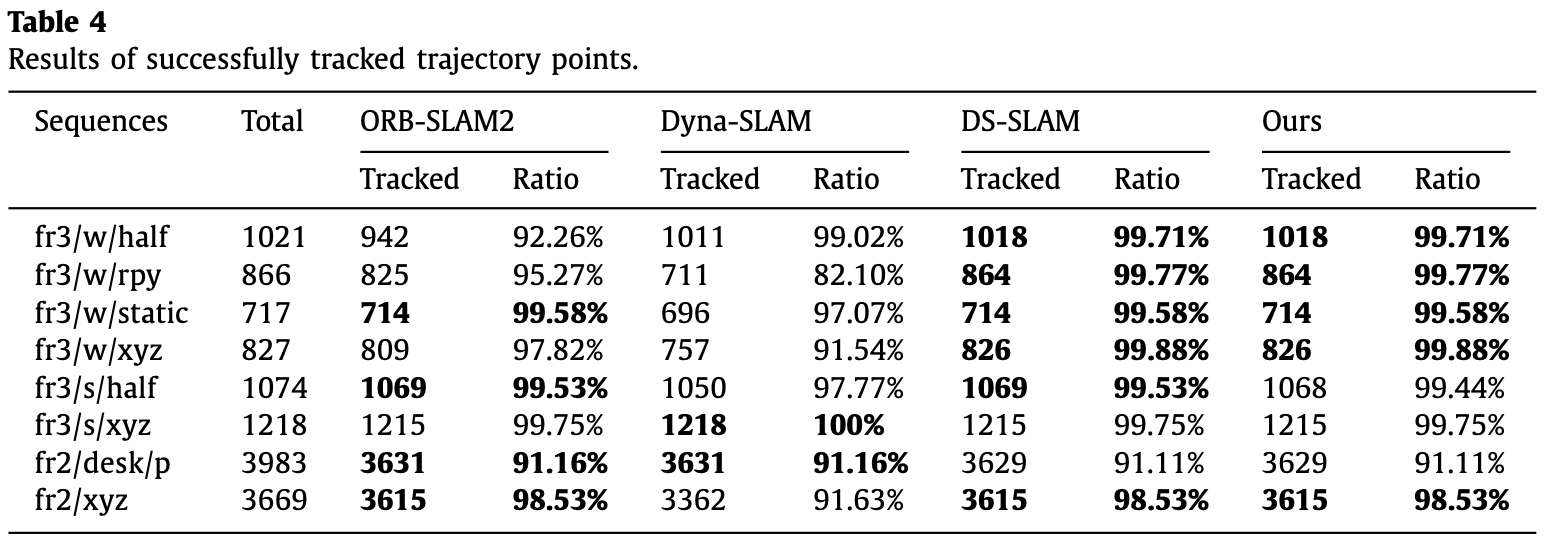
3.2 Evaluation of the Point Cloud Map
- Fig.11 为 moving objects 移除的效果(第二行和第三行为原始掩码和矫正掩码):

- Fig.12、Fig.13 和 Fig.14 分别为高动态、低动态环境和静态环境下的建图结果:



3.3 Evaluation of Processing Time

3.4 Evaluation in the Real-World Environment


参考
- [1] N. Dvornik, K. Shmelkov, J. Mairal, C. Schmid, Blitznet: A real-time deep network for scene understanding, in: Proceedings of the IEEE international con- ference on computer vision, 2017, pp. 4154–4162.
- [2] M. Runz, M. Buffier, L. Agapito, Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects, in: 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), IEEE, 2018, pp. 10–20.