CDSFusion
对论文 CDSFusion: Dense Semantic SLAM for Indoor Environment Using CPU Computing (Remote Sensing, 2022) 的阅读总结。
论文情况
- 标题:CDSFusion: Dense Semantic SLAM for Indoor Environment Using CPU Computing
- 作者:Sheng Wang, Guohua Gou, Haigang Sui, Yufeng Zhou, Hao Zhang, Jiajie Li
- 期刊:Remote Sensing, 2022
- 源码:未开源
1 Introduction
CDSFusion 的目的是实现在计算能力有限的平台上实现稠密语义 SLAM,其能在一块 CPU 上实现同步的 UAV 定位以及稠密语义 3D 重建。CDSFusion 基于 VINS-Mono:
- RGBD 的深度信息用于提高系统的鲁棒性和准确性;
- 使用 FAST 特征替换 VINS-Mono 的 Shi-Timasi 特征,用于提高位姿估计的效率;
- 使用 PSPNet(Pyramid Scene Parsing Network)获取语义分割结果,并使用 OpenVINO 进行模型预训练模;
- 使用 3D 重建方法 Voxblox 重建稠密语义分析。
CDSFusion 由 3 个模块构成:基于 RGBD 的 VIO 模块(位姿估计)、轻量级语义分割网络(实时语义分割)、3D 重建模块(3D 模型生成)。
2 Method
2.1 Overview
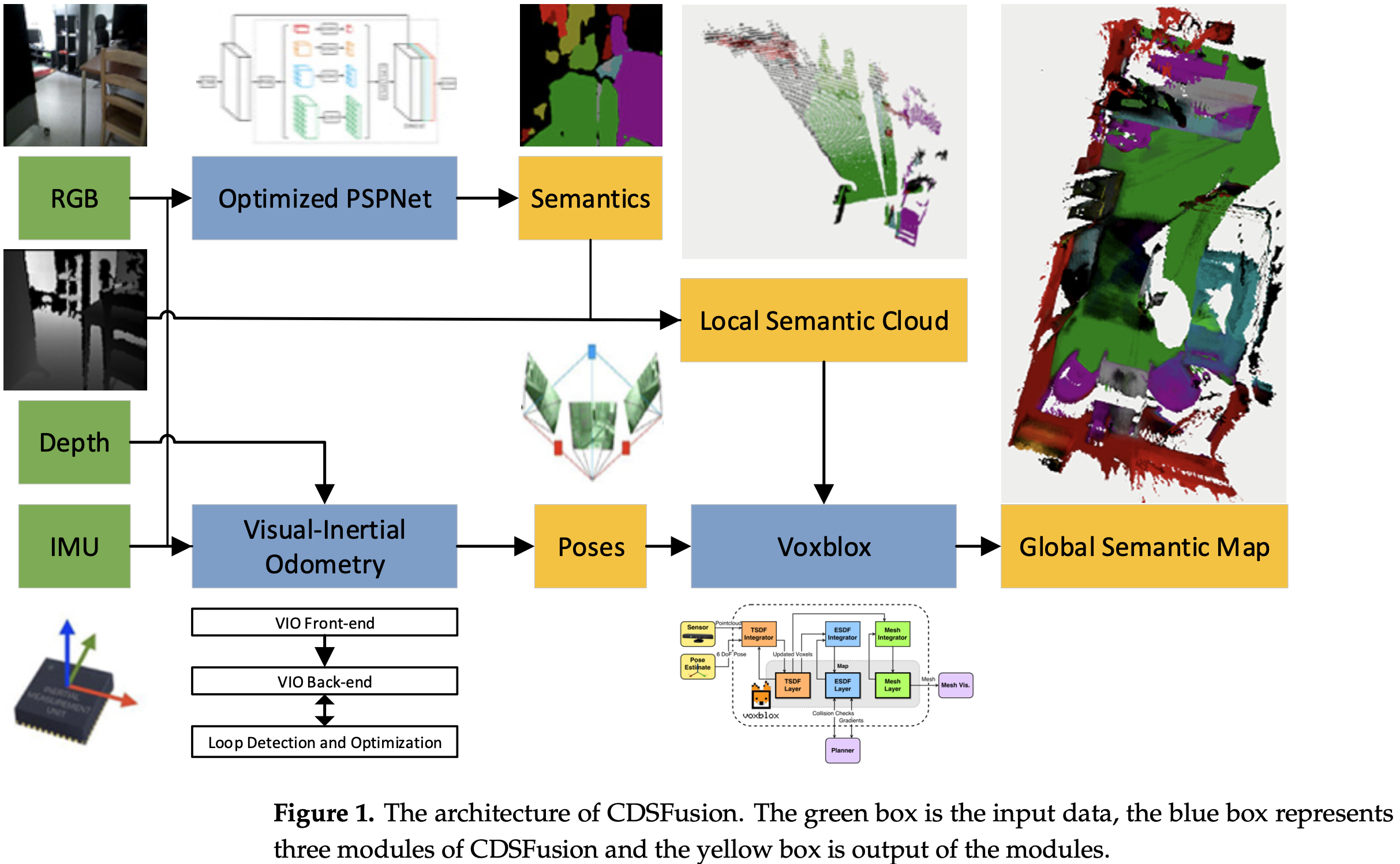
CDSFusion 以 RGB 图、深度图、高频率的 IMU 测量为输入:
- 输入的测量数据用于在基于 RGBD 的 VIO 模块估计位姿,此部分也给出高精度的全局连续轨迹估计;
- RGB 图像在语义分割模块得到实时处理;
- 在 3D 重建模块,局部语义点云使用语义图像和深度图像生成,并用于结合 VIO 给出的对应的相机位姿生成全局 3D 语义地图。
2.2 Visual-Ineratil Odometry
使用 FAST 特征替换 Shi-Tomas 特征:
- 实验结果显示,FAST 特征相比 Shi-Tomas 和 ORB 特征有相同的准确性或者更鲁棒。
所设计的 VIO 模块包含三个部分:
- 视觉惯性模块:负责处理原始传感器数据;
- 后端模块:融合处理过的测量数据以获取位姿估计;
- 回环检测及优化模块:根据检测到的回环重定位和优化位姿。
**前端模块包括 IMU 前端和视觉前端:**IMU 前端预融合原始连续两帧间的 IMU 测量数据;视觉前端使用 KLT 稀疏光流追踪连续帧上的 FAST 角点。对于每一新来的帧,追踪旧的特征,并产生新的 FAST 特征来维持图像上的特征数量。视觉前端也产生关键帧。深度信息用于初始化 VIO,以在使用 PnP 时 VIO 有精确的尺度数据。
**后端模块:**预融合的 IMU 数据、视觉和回环被添加到构成 VIO 后端的滑动窗口。若没有检测到回环,则滑动窗口不包含回环信息。在滑动窗口上使用 Ceres 进行优化。
**回环检测及优化模块依赖于 DBoW2:**对于每个关键帧,检测出 FAST 特征,并用 BRIEF 描述子作为视觉词,得到 DBoW2 的视觉数据库。然后可以使用 DBoW2 来获得回环检测的结果。回环被交付到 VIO 后端,与其他测量组成一个滑动窗口。回环检测后还包含重定位和全局位姿图优化过程,类似于 VINS-Mono。
2.3 Semantic Segmentation
语义分割方法基于 PSPNet,其原始实现是使用 Pytorch。使用 Intel OpenVINO 的模型优化器对预训练模型进行优化,使用 CPU 上的 SIMD 操作的 Infrence Engine 重新实现模型预测。由于模型优化器尚未直接支持 Pytorch,将预训练模型转换为 ONNX 格式,并使用模型优化器转换为最终模型。
语义分割模块处理每个 RGB 帧,并返回每个像素的概率向量。概率向量的值表示像素属于对应类别的概率。简单地将像素分类为与概率向量中的最大值相对应的类,并用预定义的类别颜色对它们进行着色。最终的语义图像由彩色像素组成并传递给三维重建模块。
2.4 3D Reconstruction
基于 Voxblox 构建场景的三维语义地图,主要包括构建精确的全局三维地图和对地图进行语义标注两个步骤:
- **构建精确的全局三维地图:**采用基于 TSDF 模型滤除噪声并提取全局网格。在每个关键帧,当前深度图像被转换为 3D 点云。然后采用 Voxblox,将局部 3D 点云转换为局部网格,再将局部网格集成到全局网格中。所有过程都是在 CPU 上实时处理。
- 语义标注: 3D 重建模块使用每个关键帧对应的 2D 语义标注图像对全局地图进行语义标注。 2D 语义标签来自语义分割模块。利用 2D 语义图像,可以为深度图像产生的每个 3D 点添加语义标签,从而获得局部 3D 语义点云。然后,利用 Voxblox 生成局部语义网格。结合 VIO 模块中当前帧的位姿,将局部地图融合到全局地图中。
3 Experiments
为了验证速度,评估了 VINS-Mono、ORB-VINS-Mono 和 FAST-VINS-Mono 的单帧 VIO 前端时间,主要包括特征提取和光流跟踪两个方面。在准确性方面,使用平移均方根误差(RMSE)进行精度评估:
为位姿估计和位姿针织之间的误差。
所有实验都是在华为 MateBook 13 上完成,配备 i7-8565U CPU @ 1.80 GHz,8 GB 内存和 NVIDIA GeForce MX250。为了增加实验的可信度,所提方法不增加任何加速,输入的实验数据一致,建图分辨率为0.02 m,所有其他参数使用系统默认值保持不变。实验使用 VINS-RGBD 中提供的数据集。
3.1 Feature Points Comparison
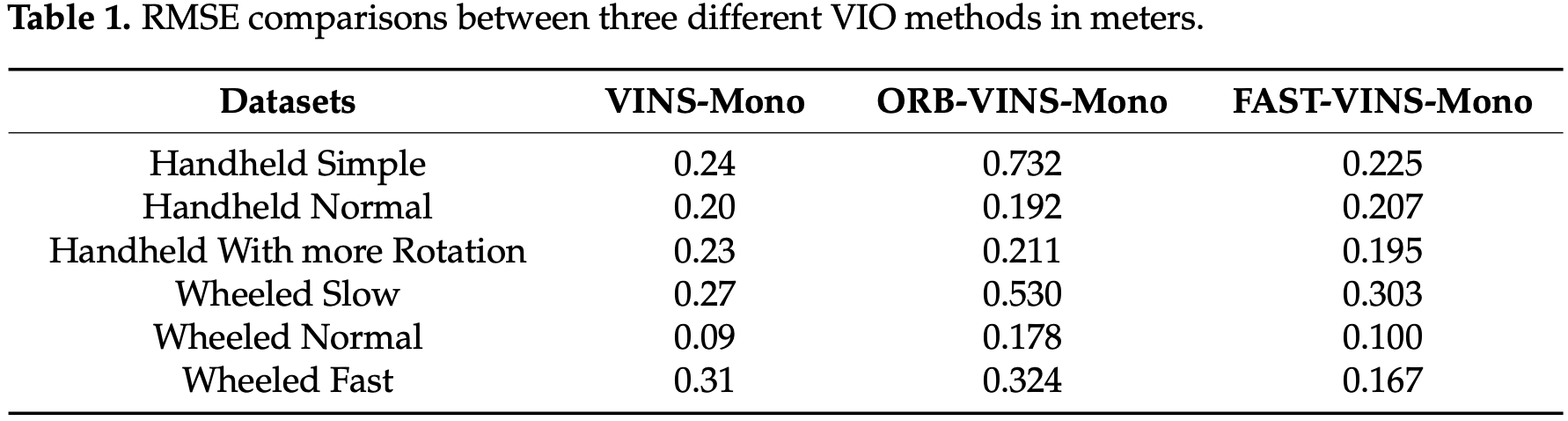
使用 FAST 特征的 VINS-Mono 获得了与原始 VINS-Mono 相当的精度。在 Wheeled Fast 数据集上,Fast-VINS-Mono 获得了相比原始 VINS-Mono 近两倍的准确率。原因是 FAST-VINS-Mono 采用快速特征进行跟踪。因此,VIO 速度更快,可以跟踪更多帧,并获得更丰富的几何结构信息,这使得 VIO 在快速运动或更多旋转时更加准确。
对于每个数据集,这 3 种方法运行 10 次,并统计成功次数来计算成功率:
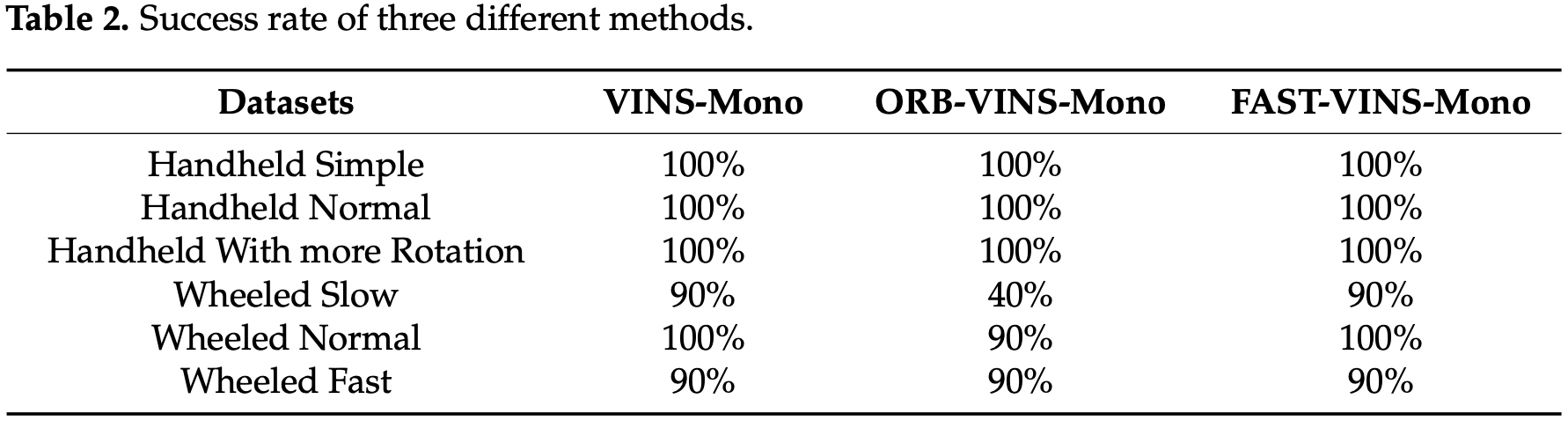
FAST-VINS-Mono 和 VINS-Mono 的成功率均超过 90%,原因可能是 ORB 特征适合用于特征匹配,但不适用于光流跟踪。还比较了这三种方法的效率在实验中统计了每帧前端的平均时间消耗:
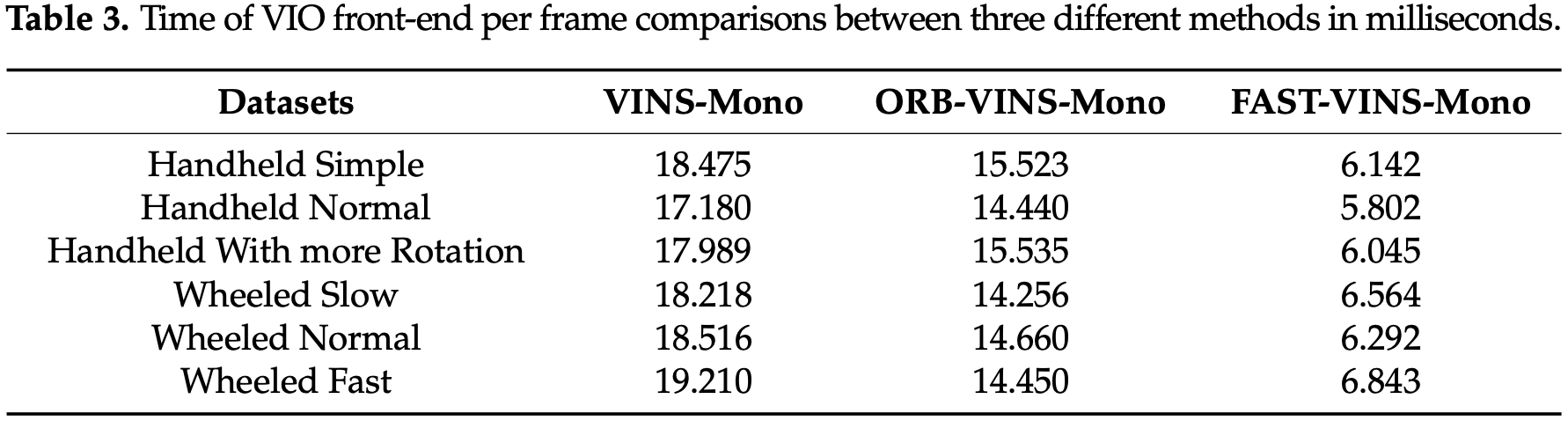
FAST-VINS-Mono 算法在精度和鲁棒性相当的情况下比原 VINS-Mono 算法更快。
4.2 Visual-Inertial Odometry
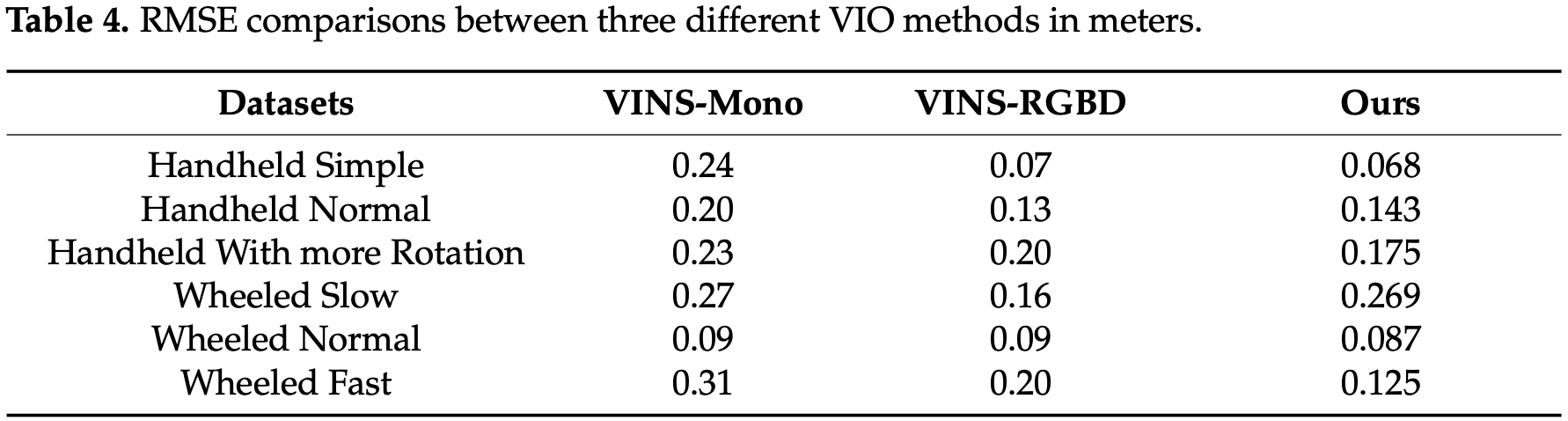
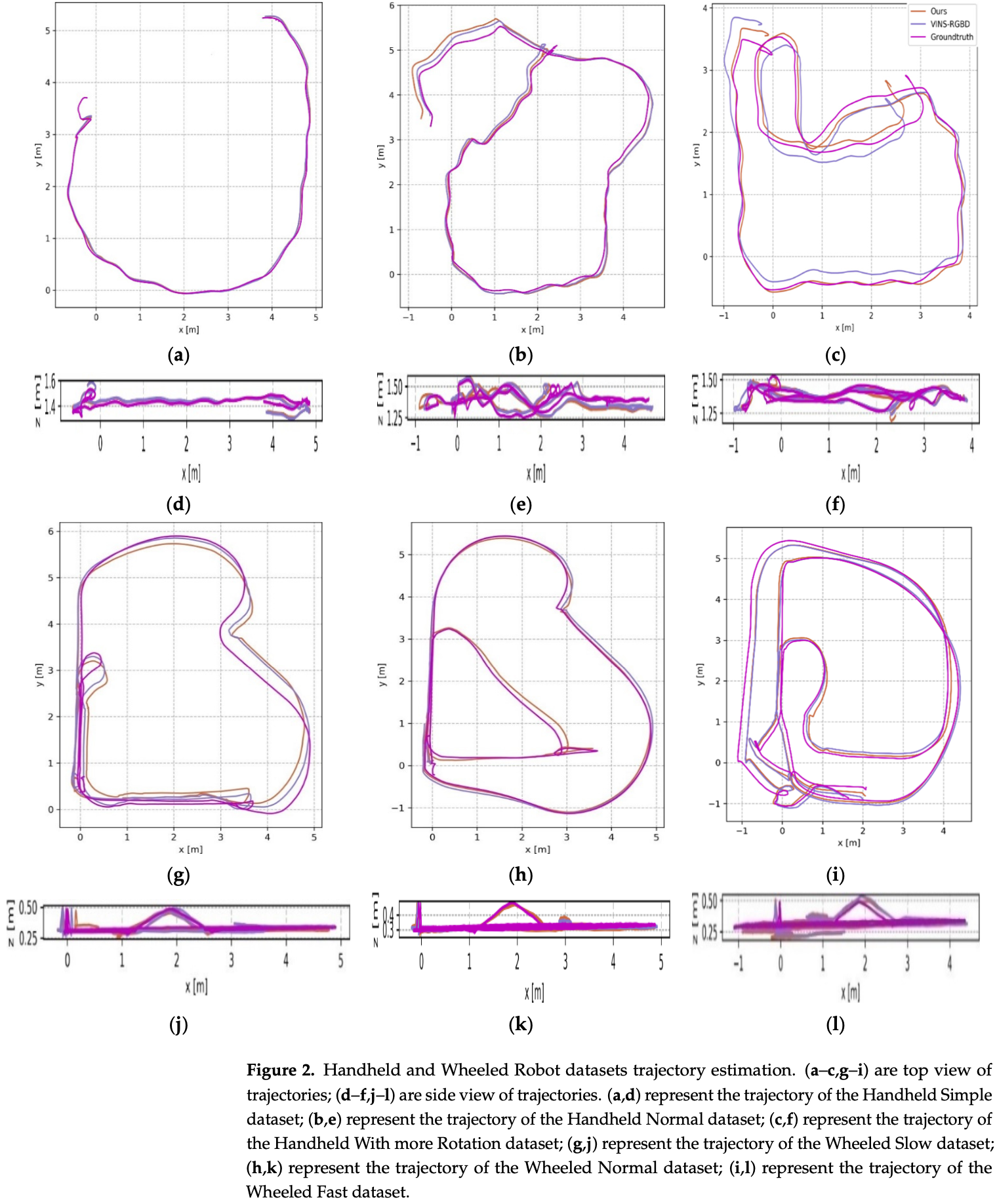
与 VINS- Mono 相比,本文方法对所有测试数据集都具有更高的精度,这主要是因为本文方法从深度信息中获得了更精确的尺度。为了直观地展示表-1 中不同方法的精度对比,这些数据集的轨迹如图-2 所示。
在实验中统计了每帧前端的平均时间消耗。时间消耗如表-5 所示:
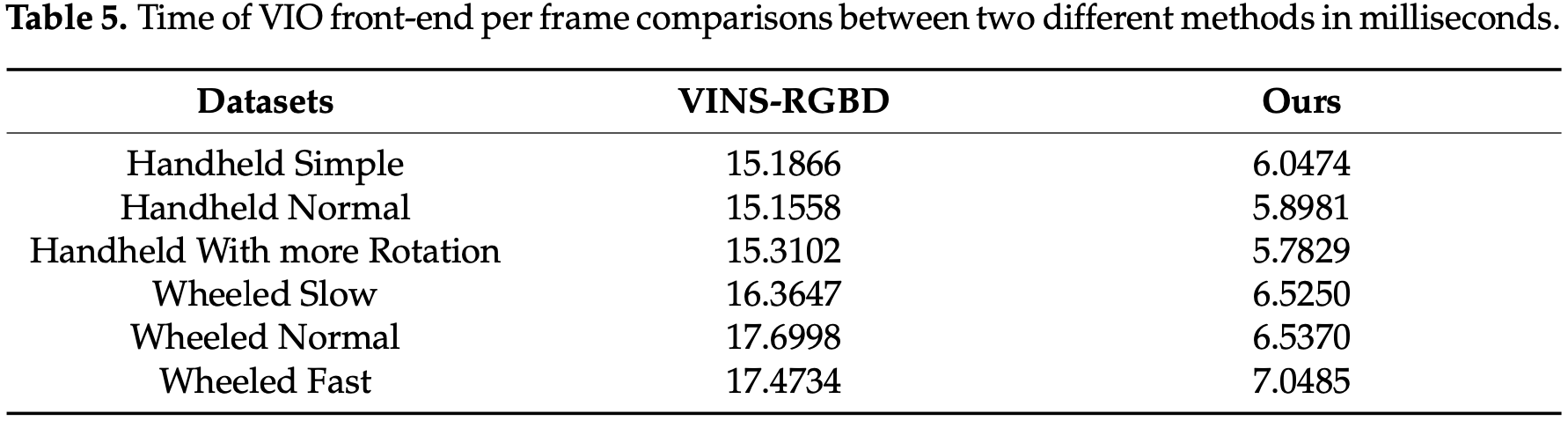
实验结果表明,与 VINS-RGBD 相比,该方法每帧整个 VIO 前端的时间快了两倍以上。VINS-RGBD 的前端类似于 VINS-Mono,提取 Shi-Tomasi 角点特征并进行光流跟踪。与它们相比,所提出方法包含一个轻量级的视觉惯性里程计,可以用于更快的姿态估计。
2.3 Dense Semantic SLAM
在两个场景中评估了所提出方法:
- 由开源项目 semantic_slam 提供的修改的房间数据集,其原始数据集没有语义地图的真实值,包括深度图像、RGB 图像和相机姿态;
- 使用 RealSense D435i 相机和 NVIDIA TX2 机载计算机的无人机记录的办公室数据集,其中包括深度图像、RGB 图像和 IMU 测量值。
- 两个数据集的真实 3D 地图,包括语义地图和纹理地图,由 BundleFusion 给出,语义分割结果由使用 SUNRGBD 训练的 PSPNet 预训练模型获得。
其他方法很难在计算资源有限的硬件平台上重建完整的环境 3D 语义地图,为了进行对比,展示了使用 GPU 加速方法生成的完整场景的 3D 语义地图和 Kimera 生成的语义地图。用于比较的方法采用相同的 PSPNet 预训练模型,但没有对模型剪枝进行优化,其余部分与 CDSFusion 相同。在接下来的实验中,将该方法称为GDSSLAM(GPU-Based Dense Semantic SLAM)、CDSSLAM(CPU-Based Dense Semantic SLAM)来表示不需要 GPU 加速。语义信息图例如图-3 所示,数据集的重建结果如图-4 所示。
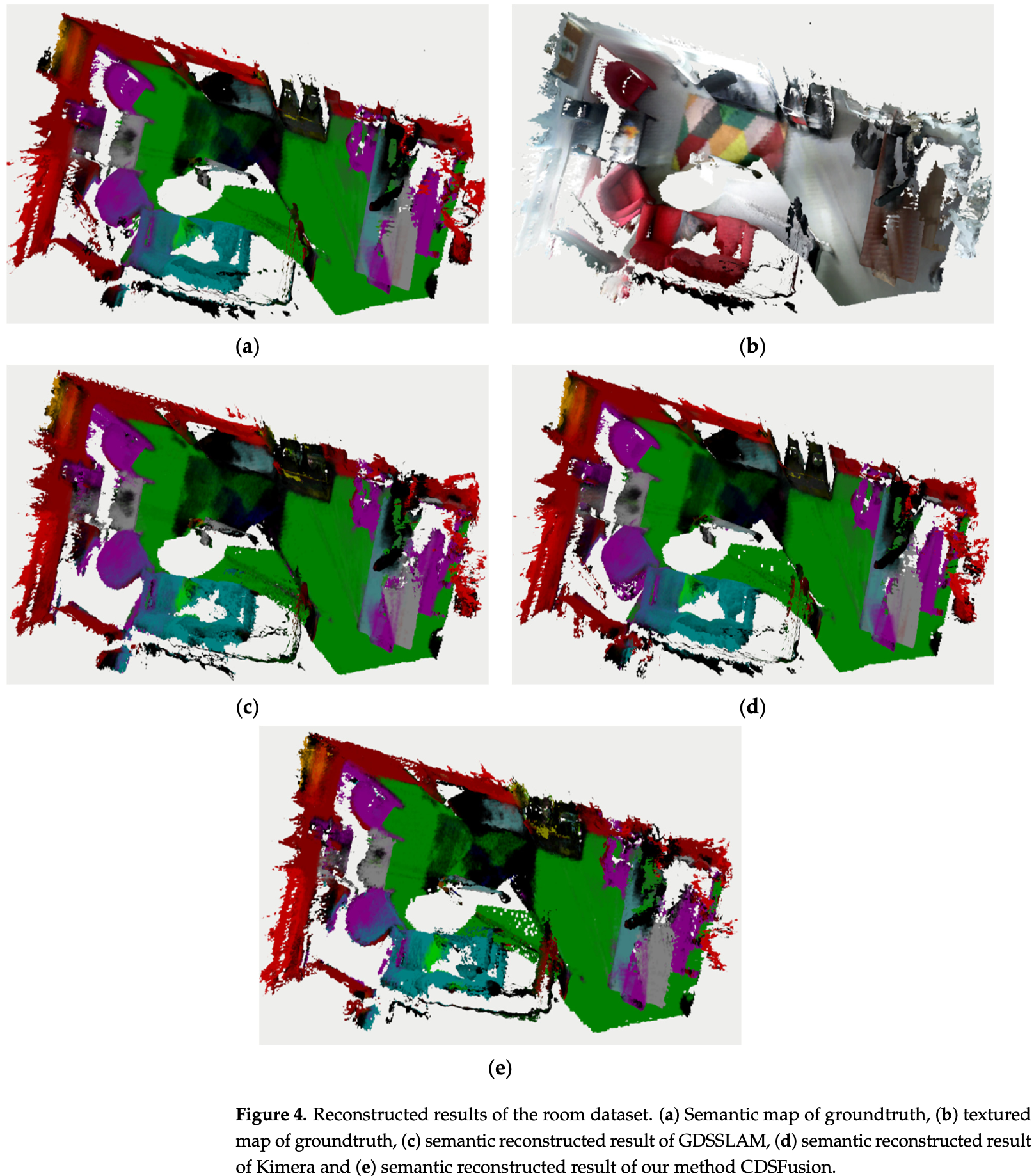
重建的 3D 语义地图,其完整性与使用 GPU 加速的 GDSSLAM 的语义重建结果相同,如图-4 c, e 所示。与 Kimera 的结果相比,Kimera 由于是离线进行语义分割,所以总体上取得了更好的性能,如图-4 d, e。
还展示了使用无人机在办公室飞行时获得的数据集的重建结果,如图-5所示。

在实验中统计了方法在处理两个数据集时的平均每帧耗时,如表-6 所示。

与 CDSSLAM 相比,CDSFusion 仅依靠一个 CPU 就将测试数据集上的每帧处理速度提高了 3 倍以上,在 office 数据集上的速度甚至接近 GDSSLAM。为了验证模型优化的有效性,还设计了实验来研究不同方法在语义分割中每帧的时间消耗。在实验中统计了三种方法在处理两个数据集时的平均每帧耗时,如表-7 所示。

CDSSLAM 在语义分割上消耗了大量的时间,这是导致语义地图生成速度慢的主要原因。GDSSLAM 借助专用图形处理器的加速大大提高了分割速度,从而实现了实时语义分割和地图生成。与 CDSS- LAM 相比,CDSFusion 仅依赖一个CPU,在测试数据集上的每帧分割速度提高了 3 倍以上,在 office 数据集上的速度甚至接近 GDSSLAM。
4 Conclusions
文中提出了一种基于 CPU 计算的室内密集语义 SLAM 系统 CDSFusion,能够在 CPU 上同时实时处理视觉惯性 SLAM、语义分割和密集三维重建的系统。CDSFusion 是模块化的,允许替换每个模块或单独执行每个模块,因此可以通过使一个模块表现更好来改进系统。
**未来展望:**VIO 模块对相机的快速运动很敏感,可以提高 VIO 在相机快速运动中的鲁棒性和准确性。另一个研究方向与密集语义地图的准确性有关,本文的研究只考虑了完整性,但准确性也很重要。更高的精度要求更精确、更轻量的语义分割网络和实时重建。可以尝试优化其他一些网络,如 MobileNetV3,并加速网格重建。