Cylinder3D
关于论文 Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation (CVPR 2021) 的阅读总结。
论文信息
- 题目:Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation
- 作者:Hui Zhou, Xinge Zhu, Xiao Song, Yuexin Ma, Zhe Wang, Hongsheng Li,Dahua Lin
- 期刊/会议:CVPR 2021
1 介绍
Cylinder3D 是一个使用三维激光雷达对 3D 点云进行语义分割的算法,其主要贡献有:
- 研究了最先进的网络架构和不同的点特征表示,揭示了直接处理点云而不需要 3D 到 2D 投影是获得卓越分割性能的关键。
- 提出了一种柱面分割点云编码方案,该方案更好地遵循了三维驾驶场景点云的固有分布规律,并开发了一种基于三维卷积的框架。其中,设计了非对称残差块作为基本模块,并提出了一种新的维分解块,以循序渐进的方式探索上下文。
- 提出的 LiDAR 分割算法在驾驶场景语义分割基准上的性能优于目前最先进的分割算法,有 6% mIoU 的增益。
2 Methodology
2.1 3D 点云的学习
三维点表示研究室外场景点云与室内场景点云有显著差异:
-
一个驾驶场景点云可能覆盖非常大的区域,可达 100 多米。
-
通常包含较多的点( > 10 万个点),但比室内场景稀疏很多。
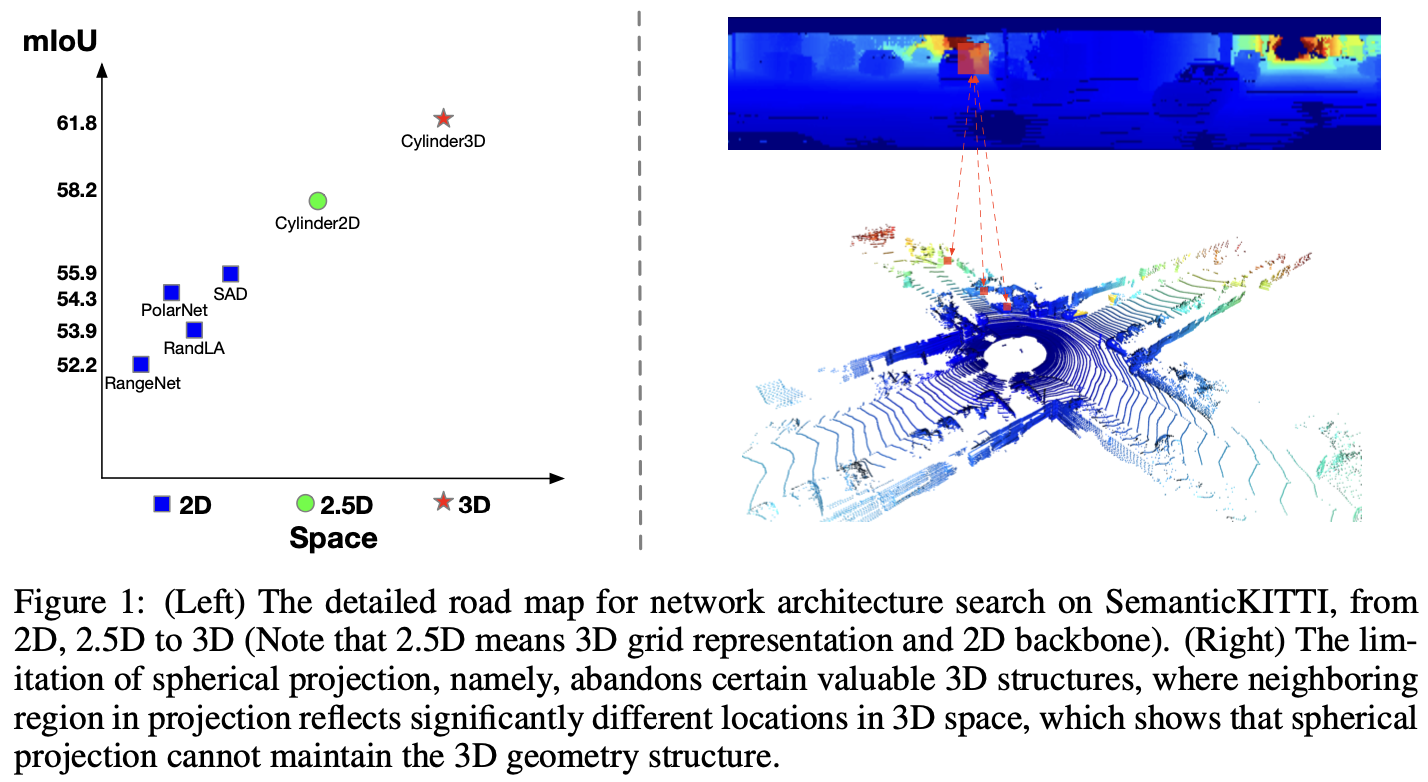
因此,针对稠密点和固定数量点的室内分割方法难以适应点密度变化巨大的驾驶场景。现有的户外激光雷达分割方法主要是通过投影将 3D 点云转化为 2D 表示,包括球面投影和鸟瞰投影,然后采用 2D 卷积处理 2D 网格表示。
然而,如图-1(右),2D 网格表示中的局部空间格局并不能很好地捕捉三维几何结构。2D 网格中的红色框代表了分布在不同空间位置的点,3D-to- 2D 投影方法可能无法对某些 3D 几何结构进行编码,导致模式提取不准确。
对 2D、2.5D 和 3D 之间的各种分区和网络进行了广泛的实验,从结果来看,一致的性能增益表明了 3D 分区和 3D 网络的有效性。
2.2 具体框架
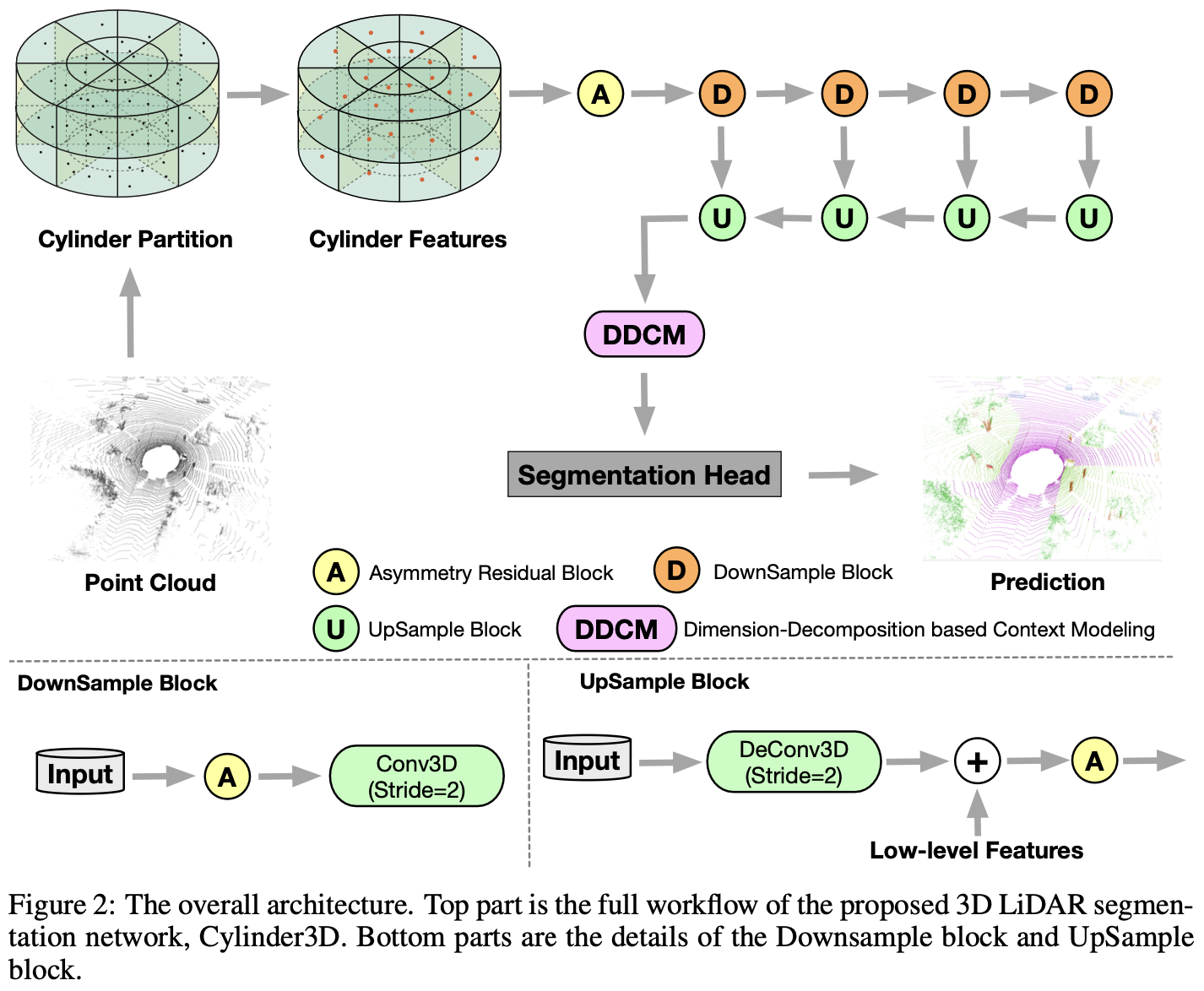
室外点云覆盖了大量不同的城市场景,语义分割的目的是为点云中的每个点分配一个语义标签。通过投影获得的 2D 表示会放弃许多可用的 3D 结构。因此,提出了一种新的基于 3D 表示和神经网络的户外激光雷达分割方法。
如图-2 所示,该框架由两个组件组成:
- 3D 柱面分区(获取 3D 表示);
- 3D U-Net(处理 3D 表示)。
特别地,设计了两个模块来适应户外点云的特性:
- 非对称残块(Asymmetrical Residual Block):匹配经常出现在驾驶场景中的长方体状的物体(汽车、卡车、摩托车等);
- 基于维度分解的上下文建模模块(Dimension-decomposition based Context Modeling Module,DDCM):以分解聚合的方式对点云中的高阶上下文信息进行挖掘。
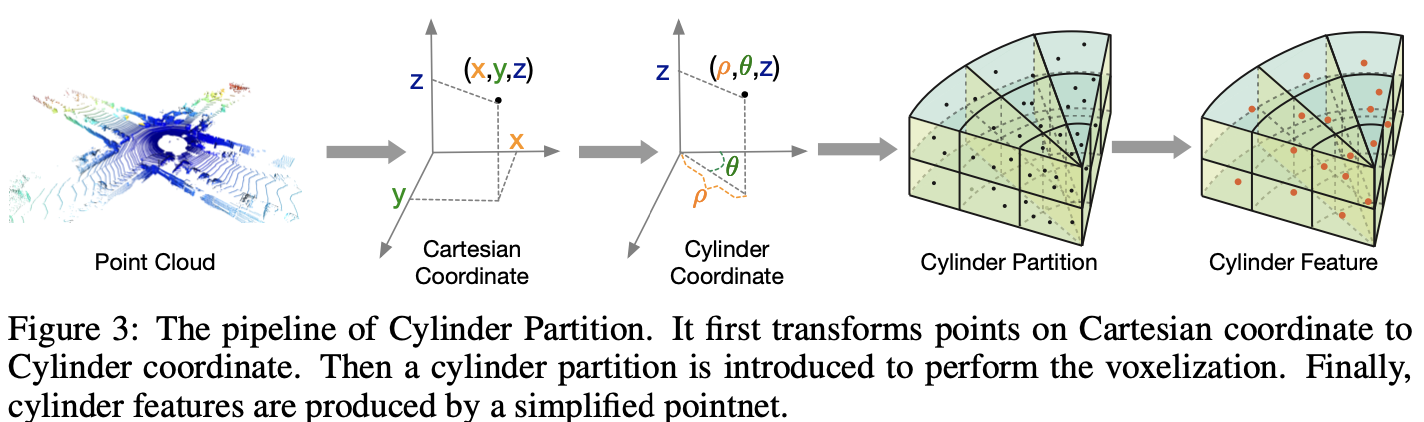
2.3 Cylinder Partition
室外场景 LiDAR 点云具有区域密度变化巨大的特性,附近区域的密度远大于远区。因此,使用圆柱坐标系来代替笛卡尔网格划分:利用逐渐增大的网格覆盖较远的区域,使点在不同区域的分布更加均匀,与室外点的分布相匹配。
此外,与基于投影的方法将点投影到 2D 视图不同,圆柱坐标系保留了 3D 网格表示,从而保留了物体的几何结构。
流程如图-3:
-
先将直角坐标系上的点变换到柱面坐标系,在柱面坐标系下计算半径 和方位角 ,变换点 到点 ;
-
柱面分割是为了均匀地分割这三个维度(注意:这种分割表示区域越远,体素越大)。
-
将这些柱面网格表示输入基于 MLP 的 PointNet 以获得柱面 point-wise 特征。
经过这些步骤,可以得到 3D 柱面表示 ,其中 表示特征维数, 表示某一圆柱块。
2.4 非对称残差块
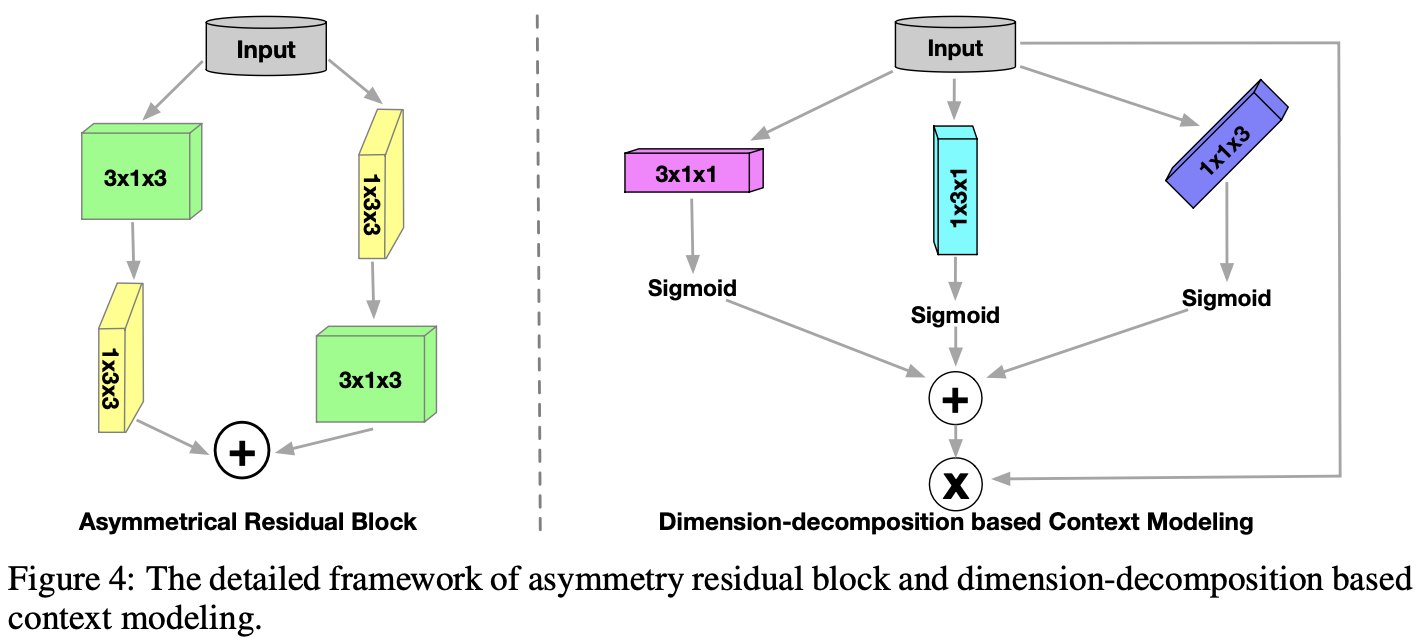
在自动驾驶场景中,存在大量的长方体物体,包括汽车、卡车、公共汽车和摩托车。通过采用不对称卷积核对矩形目标区域进行匹配,因此设计了非对称残差块来满足这类长方体对象的特性,同时显著降低了传统 3D 卷积核的计算成本。
具体地,使用内核 的卷积后,使用内核 的卷积。相当于滑动两层网络,其接受域与内核 的卷积相同,但比一个输出相同数量结果的 卷积与减少了 33% 的计算成本。
非对称残差块是下采样块和上采样块的基本组成部分(如图-2):
- 下采样块由一个非对称残差块和一个 的 3D 卷积组成。
- 上采样块融合了低阶特征,并用非对称残块对融合特征进行处理。
2.5 DDCM 模块
由于上下文的差异较大(对于 3D 空间,其上下文在点云与点云之间存在巨大的差异),因此上下文张量应该是 high-rank(高阶)的,才有足够的容量对上下文信息进行编码。
为这个上下文特征建模需要巨大的成本,特别是在 3D 空间中(上下文的高阶性)。受高阶矩阵分解理论的启发,可以将高阶上下文分解为几个低阶表示:
- 这个高阶上下文可以被划分为三个维度:高度、宽度和深度,而三个片段都是低阶的。
- 然后,使用这些片段构建完整的高级上下文。
通过这种分解-聚合策略处理了基于低阶约束的不同视角的高阶困难。如图-2(下)所示,三个秩为 的核(,,)在所有三个维度上生成这些低阶编码。然后 Sigmoid 函数对卷积结果进行调制,生成每个维度的权值,其中基于不同视图的秩 1 张量挖掘共现上下文信息。聚合所有三个低阶上下文的激活结果,获得表示完整上下文特征的整体。
2.6 Point-wise 细化模块
区块检测的方法是目前常用的方法,但不管是基于立方体还是基于圆柱体的方法都有一个不可避免的缺点,即不同类别的点可能被划分到同一个 cell(voxel)中,这将导致导致信息的丢失而影响精度。而采用块点结合的方式,能够有效的缓解错误 cell-label 编码的干扰,而提高识别的精度。
**具体的实现方式:**首先,基于 point-voxel 映射表将 voxel-wise 特征投影到 point-wise。然后,point-wise 模块将 3D 卷积网络前后的点特征作为输入,并将它们融合在一起以细化输出。
在得到 voxel-wise 的 feature 之后,可以映射回 point-wise,然后再使用 MLP 得到 point-wise 的 label。
获得 voxel 的 label,然后将当前 voxel 中的所有点预测为统一个 label。
2.7 网络优化
柱面划分利用具有 BatchNorm 和 ReLU 的 4 层 MLP 网络提取每个点的点特征,并在体素内,做 channel-wise 的 max 提取出体素特征。3D 分割 backbone 来源于 UNet,其中 3D 卷积是改编的稀疏卷积。如上所述,用非对称残块代替传统残块,并在最终预测前插入 DDCM 模块。
分割主干的输入为 张量。分割头采用一个 核的 3D 卷积层作为轻量级的分割头。经过整个 pipeline,得到基于体素的预测,其大小为 ( 为类别数量)。
对于网络优化,使用加权交叉熵损失和 lovasz-softmax 损失,以最大限度地提高类的点精度和交叉-联合得分。两种损失的权重相同。因此,总损失是:
在优化器中,使用初始学习率为 的 Adam。
3 实验
3.1 数据集和评估
-
数据集:SemanticKITTI。
-
评估:在所有语义类别上使用 (平均交并比)度量,其中
表示在类别 上的交并比, 为所有 的均值。
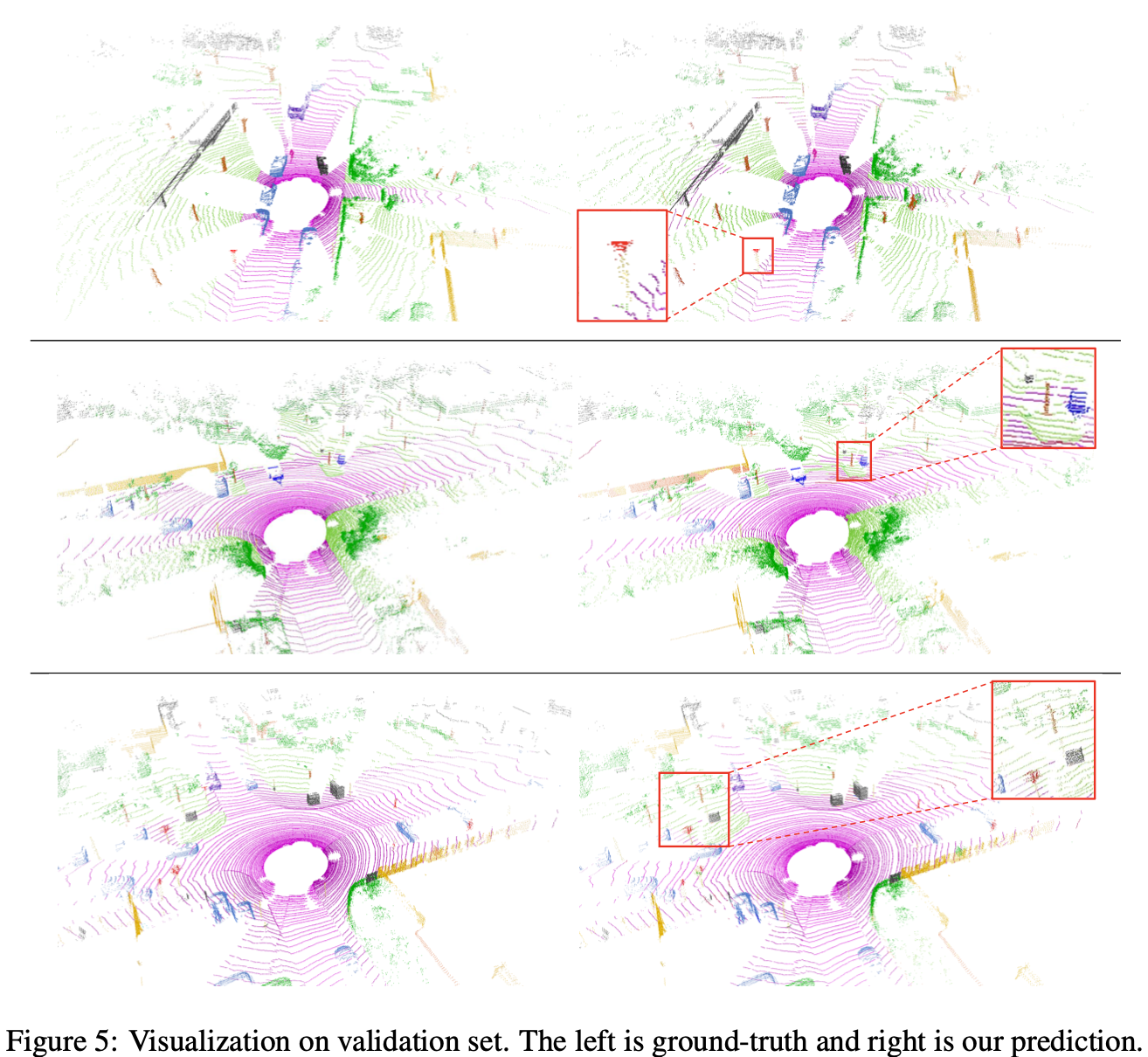
3.2 试验结果可视化