Smartphone Indoor Navigation with Leader-Follower
对论文 Smartphone-Based Indoor Visual Navigation with Leader-Follower Mode (ACM Transactions on Sensor Networks 2021) 的阅读整理。
论文情况
- 题目:Smartphone-Based Indoor Visual Navigation with Leader-Follower Mode
- 作者:Jinggao Xu,Erqun Dong,Qiang Ma,Chenshu Wu,Zheng Yang
- 期刊:ACM Transactions on Sensor Networks 2021
- 源码:未开源
1 Introduction
1.1 传统导航 V.S. P2P 导航
- 传统的导航技术:需要特定的基础设施,并且在相关区域(area-of-interest)预先适当设置。
- P2P 导航:避免预先安装室内定位服务。一个名为 leader 的旅行者记录跟踪信息(例如转弯和默写环境属性),通过互联网将其分享给需要前往统一目的地的后一个 follower。
- 例:自部署的导航服务,通过其他顾客从进入商场到走进商店的轨迹,并提供给潜在的顾客。
1.2 P2P Leader-Follower Mode
-
已有工作:利用环境 WiFi 信号、传感器数据、手机捕获的图像作为跟踪属性,同步 leader 和 follower 的跟踪。
缺点:Wi-Fi 信号的动态变化和传感器误差。
-
改进:视觉 SLAM 的成熟与运用,移动设备视觉处理能力的提升。作者提出的 Pair-Navi[1],无需专门安装基础设施、预先部署定位服务或室内数字地图。
1.3 Pair-Navi
Leader 秩序沿着路线行走并记录下视频,通过云端将轨迹视频分享给潜在的 follower。
Pair-Navi 使用视频通过 SLAM 构建 leader 走过的轨迹。Follower 则以 leader 的轨迹为参考,同时 Pair-Navi 也捕获 follower 的实时视频,精确定位 follower 与参考轨迹的相对位置,以及时把导航提示推送给 follower。

缺点:P2P 导航忽略了对导航偏差的处理。
1.4 Challenges & Solution
将视觉 SLAM 融入鲁棒的导航系统的挑战:
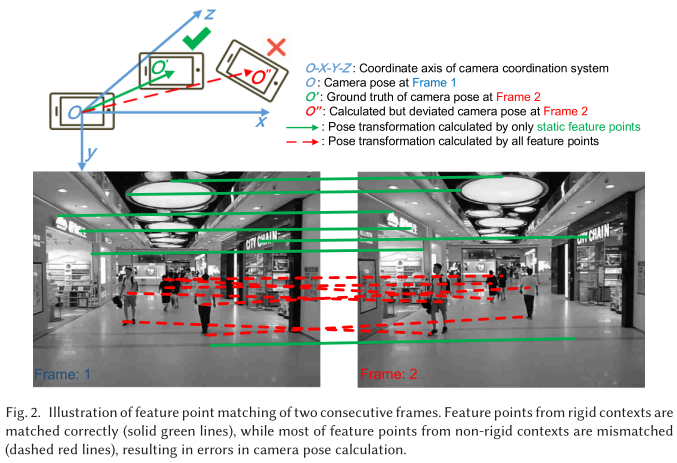
- Environmental Non-Rigidity(环境非刚性):流行的 SLAM 假定环境刚性或静态,SLAM 运行时周围环境不发生变化。现实中,有大量移动中的物体,如图-2,这种环境非刚性会导致视频帧匹配出错,影响 SLAM。
- Real-time(实时性):视觉 SLAM 包含里程测量和优化等核心计算需要大量计算成本,不适用于商用手机。同时导航应用应该精确定位用户、提供路径和提示,相反有需要实时性。
针对上述两个问题,Pair-Navi 给出了如下的解决思路:
-
Environmental Non-Rigidity:建议对轨迹中涉及的动态前景进行提取消除,保留刚性部分用于 SLAM:
- (1)筛选动态前景后,剩下的室内环境有足够的刚性特征;
- (2)深度学习的应用使得高效、动态地检测和分割视频内部的非刚性动态内容成为可能。
基于上述两点,使用基于 Mask Region 的 CNN(Mask R-CNN)来识别非刚性对象,使用从用于 SLAM 的视频特征数据集中将其筛选出来。
-
Real-time:Pair-Navi 给出了解决方案,将 SLAM 解耦后组装必要的模块。对于 follower,不使用完整 SLAM,只进行重定位。将视觉导航模块和非刚性上下文剔除模块采用同步策略。
1.5 Contribution
- 系统:在 ROS 上实现,手机端则为 ROS-Android[2]。
- 环境:三栋不同条件的建筑中进行 2 周的综合测试。
- 贡献:
- 提出了第一个用户友好的基于视觉的 P2P 导航系统,不需要测量建筑、不依赖预先部署的室内地图服务;
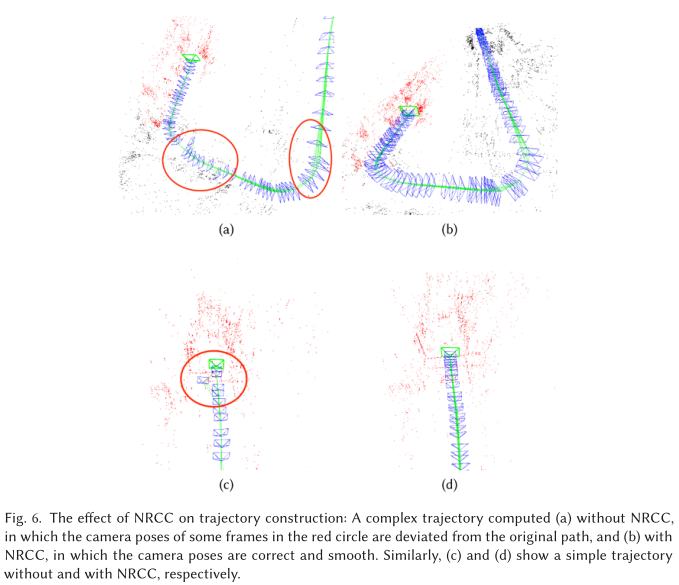
- 利用 Mask-RCNN 进行非刚性上下文剔除(Non-rigid Context Culling,NRCC)。在 Tum 和 KITTI 数据集上的实验表明 NRCC 提高了定位精度和建图精度。
- 在商用手机上实施并验证了完整的实时系统,评估其性能。
2 Overview
2.1 Peer-to-Peer Navigation
- Pair-Navi 无需室内数字地图。
- 重复利用早期 leader 的经验,任何走过一条路的人都可以通过提供相应的轨迹信息(Wi-Fi 信号序列、地磁序列、IMU 传感器测量、视频、航向、转弯、上坡等)作为该特定路径的导向。
- follower 通过请求数据,将 follower 的相对位置与 leader 的参考轨迹进行同步。
- 不同场景下,用户在 leader 和 follower 间转换。
2.2 System Overview
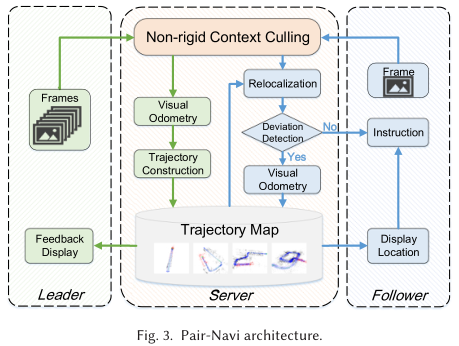
如图-3,leader 和 follower 都同时沿着道路行走,手持智能手机拍摄视频。手机拍摄到的每一帧都传回云端进一步处理。
leader 有三个模块:Initialization、Visual Odometry、Trajectory Construction。形成一个轨迹(3D 相机姿态序列)和一个地图(3D 地图点和关键帧)。轨迹和地图数据,连同 leader 标记的起点和终点被存在服务器上。
当 follower 到达,其先选择目的地,并会得到某个 leader 提供的指向同一目的地的参考轨迹。follower 行走时,系统根据捕获的视频帧,重定位其位置到参考轨迹。重定位成功,则 follower 获得导航提示;若失败,follower 会在后面的过程中偏离路径,触发偏差检测模块,启动独立视觉里程计,独立跟踪 follower 的相机位姿。
3 Visual Navigation in Non-rigid Environment
3.1 Visual SLAM for Navigation
3.1.1 Initialization
当系统启动时,使用极线几何(epipolar geometry)进行初始化,以 3D 地图点作为环境的坐标,在初始地图中定位相机,步骤如下:
- 相机捕捉两个早期帧,从中提取和匹配能描述帧的特征点(如图-5 (a))。此处使用 ORB 特征点。
- 前两帧间的相对位姿变换记为 ,其中 表示坐标系,通过求解极线约束方程求解得到。设第一帧的坐标系为世界坐标系 ,即 。
根据相机在不同帧之间的运动,由三角化算法(triangulation)计算特征点的深度。三角剖分后可以得到相机坐标系中每个特征点的 3D 坐标。
由于第一帧设置为世界坐标系,因此可以得到每个特征点在世界坐标系的 3D 坐标,并相应地建立一个环境的初始稀疏三维地图。
3.1.2 Visual Odometry
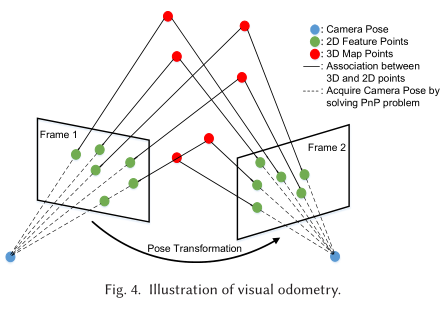
初始化后,VO 模块从连续的视频帧中跟踪相机的姿态。具体地,当一个新的帧到达,其 2D ORB 特征被提取,通过特征匹配与已经创建的 3D 地图点进行关联。
图-4 展示了与 3D 地图点相关联的特征点提取匹配示例。从 2D 特征和 3D 地图点的匹配,可以通过 PnP 问题来获得这一帧相机的姿态:
- PnP 问题通过 3D 点和 3D 像素点之间的一组对应关系来确定相机的位置和方向。
如图-4,给定两帧相机姿态,通过三角剖分计算 3D 坐标可以生成新的 3D 地图点。随着更多新帧的到来,可以建立起相机姿态轨迹、3D 地图和对应的关键帧。
3.2 NRCC
3.2.1 Limitations of Visual SLAM in Non-Rigid Environments
-
Low-Precision Trajectory(低精度轨迹):错误的特征点匹配将影响轨迹精度。上图-2 中即为两个连续帧的匹配,可以看到红线匹配的动态物体会导致大的匹配错误。因此需要对背景进行识别,筛选对应的特征。
-
Vulnerable Relocalization(重定位脆弱):实际中,leader 和 follower 观察的环境会发生变化,导致特征点不匹配,产生较大的重定位误差(少量的匹配 outliers)甚至重定位失败(大量的匹配 outliers)。
因此,提出 NRCC 来提取非刚性特征点,留下刚性区域和静态区域的特征点。观察结果发现,实际有大量特征点可以用于匹配,允许不降低 SLAM 性能的条件下筛去部分特征点。
3.2.2 NRCC via Mask R-CNN
Mask R-CNN 是一个实例分割框架,通过对每个实例的分割掩码(segmentation mask)来分离图像的不同实例。实验中使用 COCO 数据集进行预训练。
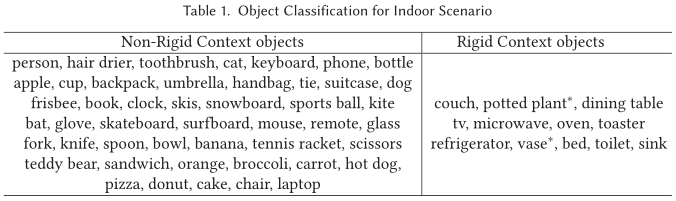
如表-1,将数据集中的类别分为刚性和非刚性。刚性对象即 leader 和 follower 来到同一地方时,对象的位置、姿态和形状不会改变;非刚性对象则相反。一些类别(如花瓶)其分类是灵活的,需要考虑 leader 和 follower 经过时的时间间隔问题。
当服务器接收到视频帧时,提取特征点,并用 Mask R-CNN 检测非刚性上下文,然后过滤非刚性特征点。同时使用 YOLO 中的方法[3] 检测帧中的镜像和光滑平面,同样进行剔除以降低不稳定性。

加入 NRCC 后的对比如图-6 中的 (a)、(b) 和 ©、(d):
4 Real-Time Navigation
4.1 Leader Trajectory Map Construction
leader 只需手持手机在身前,然后沿着轨迹行走,让手机记录下视频帧即可。结束后,leader 将标有起点和终点的视频帧上传到服务器。服务器为每一帧运行视觉 SLAM,最后构建轨迹地图并保存。
4.2 Follower Real-Time Navigation
- Client:follower 选择服务器给出的目的地,手机作为 ROS 节点运行,捕获视频帧并上传至服务器。
- Server:服务器作为 ROS 节点,加载选定的轨迹和地图,开始运行:重定位 follower 的视频帧,在 leader 的轨迹图中可视化相机位姿,计算导航指令。
follower 接到返回消息后,可以看到导航指令、当前相机姿态以及可视化的轨迹图。若重定位检测到 3D 地图点不足,则辅助 VO 从这一帧开始运行;若重定位失败,则辅助 VO 取代重定位模块来显示相机姿态。一旦重定位成功,则辅助 VO 关闭。
Pair-Navi 有如下的三种设计,确保实时运行(不低于 10 fps):
- Relocalization:对经典视觉 SLAM 进行了解耦,自适应地将重定位模块和 VO 模块组合到 follower 的导航系统中。
- Mask Synchronization Strategy:非刚性剔除对 leader 和 follower 都适用,但方法不同。
- leader:每一帧生成一个掩码,因为是离线地图构造,不用担心算力。
- follower:由于 Mask R-CNN 计算较慢,约 5 fps,采取折中策略同步掩码过程和 SLAM,聚合每两帧(0.2s 时间跨度)并为它们生成一个掩码。
- 聚合原理:假设不行为 1m/s,则 0.2s 走过 20cm,场景不会发生明显变化,不影响 follower 的重定位。因此,可以在连续几帧上重用掩码。
- The Fringe Benefit of NRCC:使用 NRCC 减少了特征点,为进一步计算降低了开销。
4.3 Follower Deviation Handling
当 follower 偏离路线时,甚至相机位姿偏离时,就会产生偏差。此时,重定位模块观测到帧中 3D 地图点不足,启动辅助 VO。
辅助 VO 提取新的特征点,生成新的 3D 地图点,于重定位并行运行,保持连续跟踪,并在轨迹图中显示相机位姿,如图-7。随着相机姿态在轨迹图中的显示,follower 可以找回到正确轨迹。一旦观测到足够的 3D 地图点,辅助 VO 则关闭,并将导航任务移交给重定位模块。
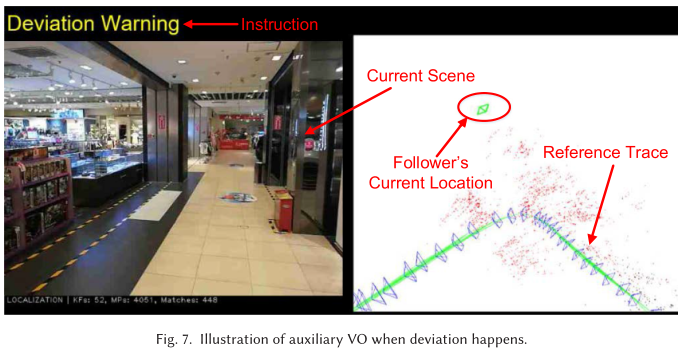
为维护辅助 VO 的运行,选择特征点数量的阈值来控制对辅助 VO 的触发。
4.4 Navigation Instruction Calculation
导航指令的计算以当前 follower 帧参照世界坐标系的位姿 ( 为世界坐标系,设置为 leader 地图的第一帧)作为输入,为每个 follower 帧在 leader 的地图中计算姿态。
由于在 leader 的轨迹中,存在一个姿态 ( 表示重定位)与当前 follower 帧的姿态最接近,因此选其为代表,并且求其在 leader 轨迹里后续 10 帧位姿中平移部分的平均值 。(选择 10 帧的理由:10 帧跨度约 1.5s,人类步幅为 0.4s - 0.6s,相当于选取接下来 2 - 3 步的走向)。
由上,将 齐次化后,可以计算:
注意所使用的坐标系如图-2 所示。
之后可以算出导航指令, 和相机平面的夹角:
此处假定 follower 以平稳的状态拿着手机。
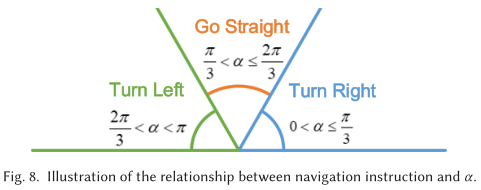
如图-8,可以得到 不同范围下,系统给 follower 发出的导航指令。注意此处假设了 leader 在建立轨迹图时没有后退的现象,因此理论上 非负,因此不需要 ”Go Backward“ 的指令。如果 真的出现负值,则说明是重定位问题,给出 ”Deviation Warning“ 指令,并触发辅助 VO。
4.5 Implementation
- 基于 ROS Kinetics、ROS-Android、ORB-SLAM on ROS
- 视频帧大小为
- Mask R-CNN 结合 ResNet-FPN-50 backbone,在 COCO 数据集与训练。
5 Experiments and Evaluation
5.1 Experiment Settings and Methodology
- 场地:办公楼、体育馆、购物中心的一至四层
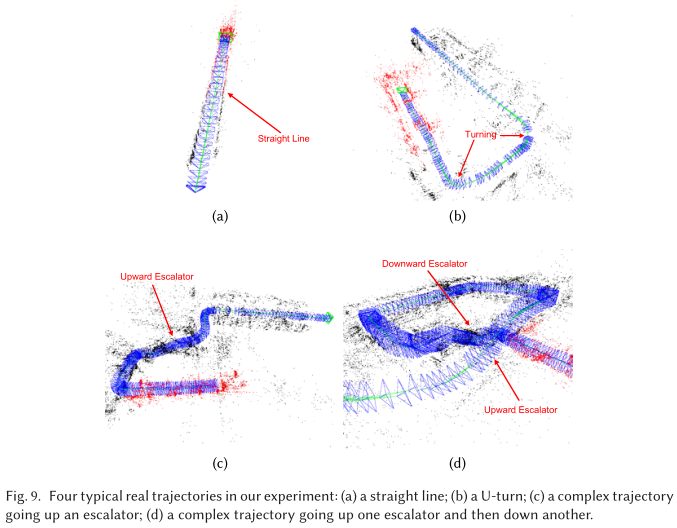
- 数据: 21 条路径,短路径 6 条(),中路径 7 条(),长路径 8 条()。leader 参考轨迹总长度约 3.1km,视频帧数 33452,关键帧数 6781,follower 总步行距离约 15km(图-9)。
- 手机:Huawei P10、Nexus 6p、Nexus 7、Lenovo Phab2 pro
- 对比:Travi-Navi[4] 和 FollowMe[5]
- 评价标准:在 21 条路径上设置 274 个 checkpoints,使用 Travi-Navi 和 FollowMe 中的评价标准,即 checkpoints 的成功到达率。由于 Pair-Navi 使用了辅助 VO,故到达率为 100%,因此这里改为 ,其中 为辅助 VO 的触发率。
5.2 Overall Performance
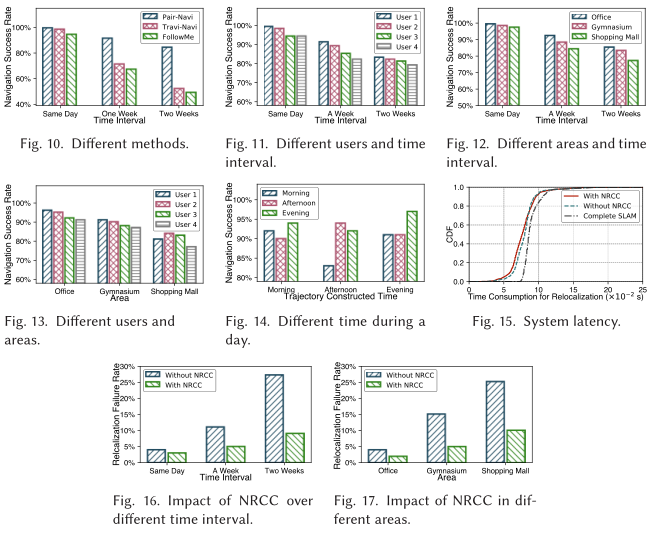
附件
1 利用三角化求点深度(线性三角化)
1.1 逻辑
向量叉乘性质(向量转为反对称矩阵):
对于三维空间点在世界坐标系下的齐次坐标 ,以及坐标系到相机坐标系到转换矩阵 , 为 的归一化平面坐标, 为深度值,则有:
由于 的前两行经线性变化可以得到第三行,故保留前两行:
由此,当获得两个及以上图像观测时,可以得到:
上述使用 SVD 求解最小二乘解,最终得到:
若给出的是像素坐标 ,且已知相机内参 ,则 3D 坐标的求解与上面类似:
1.2 代码
- VINS-Mono(使用归一化平面坐标):
1 | void FeatureManager::triangulatePoint(Eigen::Matrix<double, 3, 4> &Pose0, Eigen::Matrix<double, 3, 4> &Pose1, |
- ORB-SLAM 2:
1 | void Initializer::Triangulate(const cv::KeyPoint &kp1, const cv::KeyPoint &kp2, const cv::Mat &P1, const cv::Mat &P2, cv::Mat &x3D) |
1.3 参考
参考
- [1] E. Dong, J. Xu, C. Wu, Y. Liu and Z. Yang, “Pair-Navi: Peer-to-Peer Indoor Navigation with Mobile Visual SLAM,” IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, 2019, pp. 1189-1197, doi: 10.1109/INFOCOM.2019.8737640.
- [2] ROS Android. 2017. Retrieved from http://wiki.ros.org/android.
- [3] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2016. You only look once: Unified, real-time object detection. In Proceedings of IEEE CVPR.
- [4] Yuanqing Zheng, Guobin Shen, Liqun Li, Chunshui Zhao, Mo Li, and Feng Zhao. 2014. Travi-Navi: Self-deployable indoor navigation system. In Proceedings of ACM MobiCom.
- [5] Yuanchao Shu, Kang G. Shin, Tian He, and Jiming Chen. 2015. Last-mile navigation using smartphones. In Proceedings of ACM MobiCom.