Snap2cad
对论文 Snap2cad: 3D Indoor Environment Reconstruction for AR/VR Applications Using a Smartphone Device (Computers & Graphics 2021) 的阅读整理。
论文情况
- 标题:Snap2cad: 3D Indoor Environment Reconstruction for AR/VR Applications Using a Smartphone Device
- 作者:Alessandro Manni, Damiano Oriti, Andrea Sanna, Francesco De Pace, Federico Manuri
- 期刊:Computers & Graphics 2021
- 源码:未开源
1 Introduction
传统的室内场景重建方法基于合并大量深度图像或使用同样需要从不同视点拍摄大量照片的摄影制图(photogrammetry):
- 手机 APP——Autodesk 123D Catch 使用从不同角度拍摄的 26 张照片来重建一个物体。
重建方法对比:
- 基于 LiDAR 或 ToF:低分辨率、噪声、部分缺失。
- 基于 DL:可以通过一张 RGB 图片重构一个场景。但对于 VR 和 AR 需要一个环境的完全扫描来说,普通手机不具备深度传感器来辅助扫描。且使用单一 RGB 照片进行重建的方法并不稳定。
本文方法:
-
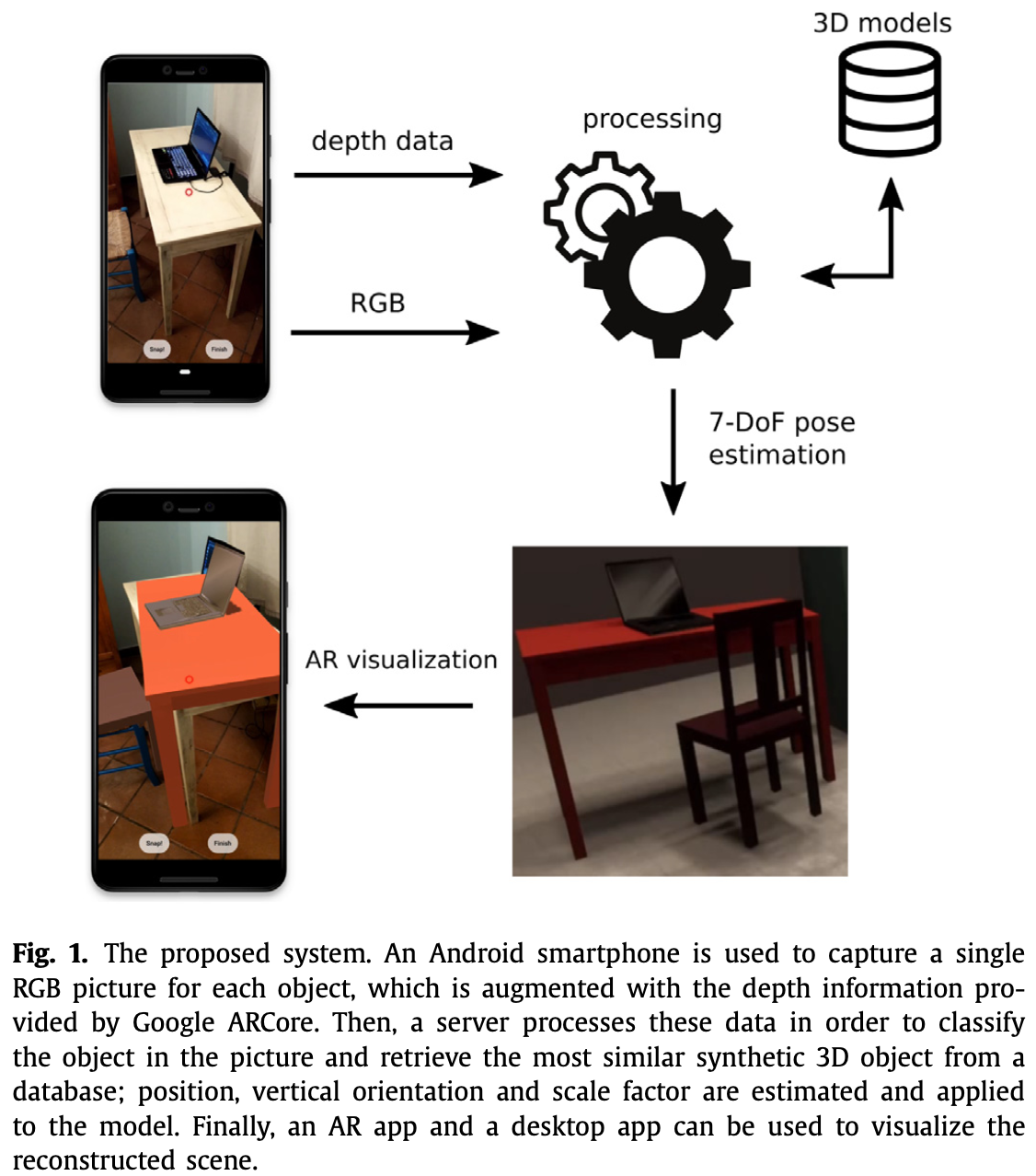
提出一个半自动的系统,用户使用手机进行对真实世界的数字化重建。手机用来捕捉物体图像,这些物体的 3D 表示将从数据库中检索出来。然后,这些图像连同深度信息一起被发送到服务器进行处理。
-
半自动需要用户进行一些手动操作:
- 用户为每个物体拍摄一张照片;
- 确定属于所框出物体的点。
-
执行步骤:
- 第一步:物体分割和分类,为每个像素分配语义标签。
- 第二步:服务器在数据库中检索与目标物体最相近的 3D CAD 模型。
- 第三步:计算物体位姿和缩放因子,计算物体在世界参考系的旋转和位置。
-
方法特点:第一个利用仅有单 RGB 摄像头的手机拍摄单角度照片,从而计算物体 7-DoF(3-DoF 位置,3-DoF 缩放,1-DoF 旋转),进行室内重建的方法。
2 The Proposed Solution
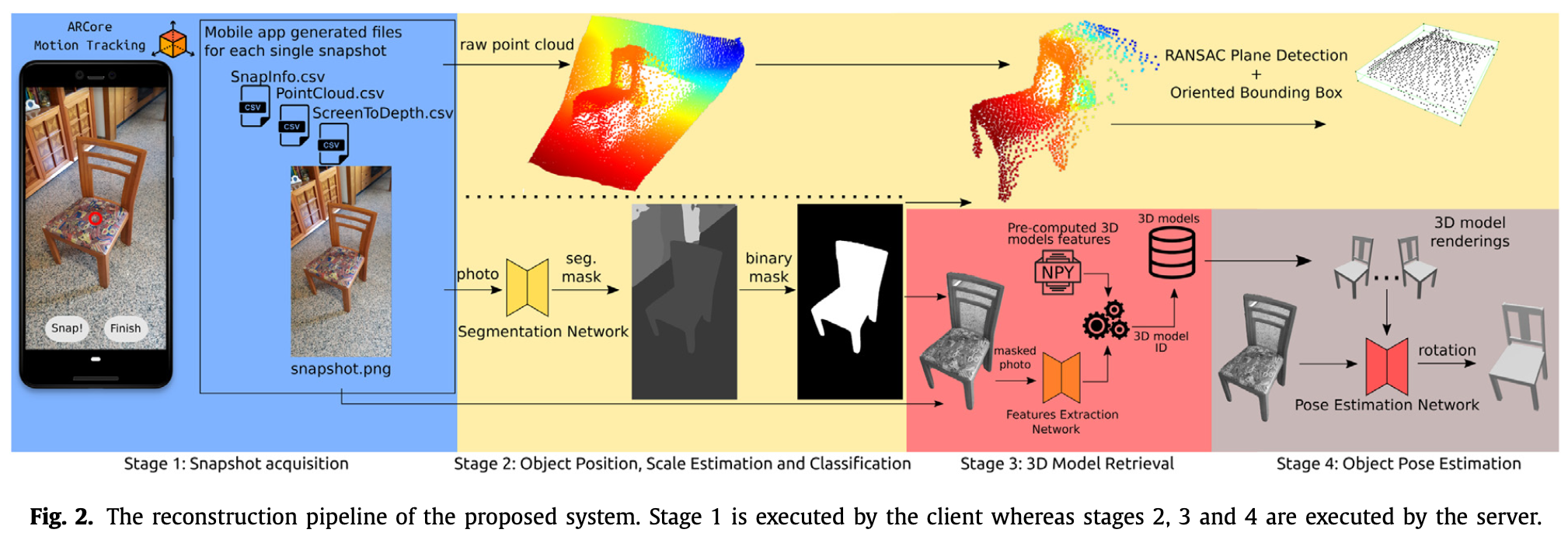
系统识别被框识出的物体,并从数据库中检索对应的 3D CAD 模型。设 为模型集合,,其中 表示 3D CAD 模型的总数。每个 属于具体的类别 。对于每个物体,其目标是推测其类别 ,找到与其最相似的 3D CAD 模型 ,并估计其 7-DoF 位姿。
系统使用安卓设备运行基于 Google ARCore 的 APP。对于每个物理物体,其 snapshot(快照、描述)由如下的内容组成:
- RGB 图像;
- 深度数据;
- 设备位姿;
- 最低水平面。
系统不需要深度传感器,因为可以使用 Visual-SLAM 和 ARCore Depth API 提供的深度图估计算法。
2.1 Snapshots Acquisition
第一个阶段通过使用 Android 手机拍摄物体的 snapshot。从 Google 提供的 DepthLab APP[1]中实现的实用程序开始,使用 Unity3D 和 ARCore Depth API SDK 开发一个 Android APP。开发的 APP 在 Unity3D 世界坐标中跟踪手机,实时预测深度地图,并检测水平面。
当 APP 开始运作,ARCore 定义一个坐标系 ,即固定其原点为起始位置 ,旋转为初始旋转 :
通过移动手机,手机位姿通过 ARCore Visual-SLAM 算法进行计算。当用户需要检索一个物体的数字描述时,需要将该物体用手机屏幕上的固定虚拟红色游标聚焦(如 Fig.2 所示)。然后,用户点击“Snap!”按键获取物体的 snapshot,这将触发如下事件:
-
APP 以相机分辨率 保存第 张单视觉 RGB 图像 。
-
APP 检查检测到的水平平面面 ,其中 为在第 个 snapshot 上检测到的平面数。位置最低的平面被视作候选地面平面,其相对手机初始位置的高度 存储为名叫 SnapInfo 的 CSV 文件:
手机相对于垂直轴的旋转 同样被保存,之后用于估计物体的旋转。
-
APP 在名为 ScreenToDepth 的 CSV 文件里存储拍摄图像 在手机屏幕空间坐标系到估计的深度地图 坐标系之间的映射关系。
因为 ARCore 计算的深度图为 px,而 RGB 图像的分辨率为 。
-
为了在给定的深度图所对应的相机空间 上构建点云,程序需要使用到相机内参,即原点 和焦距 。记 为点云中对应深度图上像素 的点, 为其深度值,则有
-
APP 在名为 PointCloud 的 CSV 文件中存储估计深度图 的屏幕空间坐标系与世界空间 3D 点的映射关系。世界空间 3D 点使用 DepthLap 中的方法计算得到。
用户重复上述操作来建模想要用 3D 模型替换的物体,并在点击“Finish”按键后结束,并将上述 CSV 文件上传到服务器。
2.2 Object Classification and Estimation of Object Position and Scale
第二阶段由服务器处理手机生成的文件。这一阶段的目的是分类每个 snapshot 中所选物体并估计其在世界坐标系的位置 和大小 。为从 RGB 图像中提取被用户锁定的物体,系统执行语义分割,给每个像素一个语义(分类)标签(使用 MSeg[2] 完成:神经网络框架为 HRNet-W48,其使用 MSeg-3m-1080p 进行预训练。)。
分割网络的输出为灰度图 ,每个像素是一个与特定语义类别相关的灰度编码。由于分割网络输出的图像与输入分辨率不同,因此将结果使用最近邻差值(nearest interpolation)缩放回 的大小。图像中心的像素保存有目标物体的颜色编码,如果颜色编码表示了一类由系统管理的物体,则服务器进一步处理图像,否则丢弃图像。
系统现在能从单视图 snapshot 点云 中提取掩码中突出显示物体的点云 。使用变换矩阵将点云从相机坐标转换到世界坐标:
然后,使用二进制掩码通过 flood fill operation 在分割图上从中心像素开始,从原始点云提取属于目标物体的点。
对于小物体,只需计算分割点云 的 3D bounding box 就可以得到物体的质心和大小。系统使用了 Open3D[3] 中的方法。另一方面,大尺寸物体则存在几个挑战:
- 1)可能由不同的部分组成;
- 2)物体的单视图可能造成点云中的 outliers;
- 3)ARCore 应用于深度图的 smoothing 可能造成 flying points。
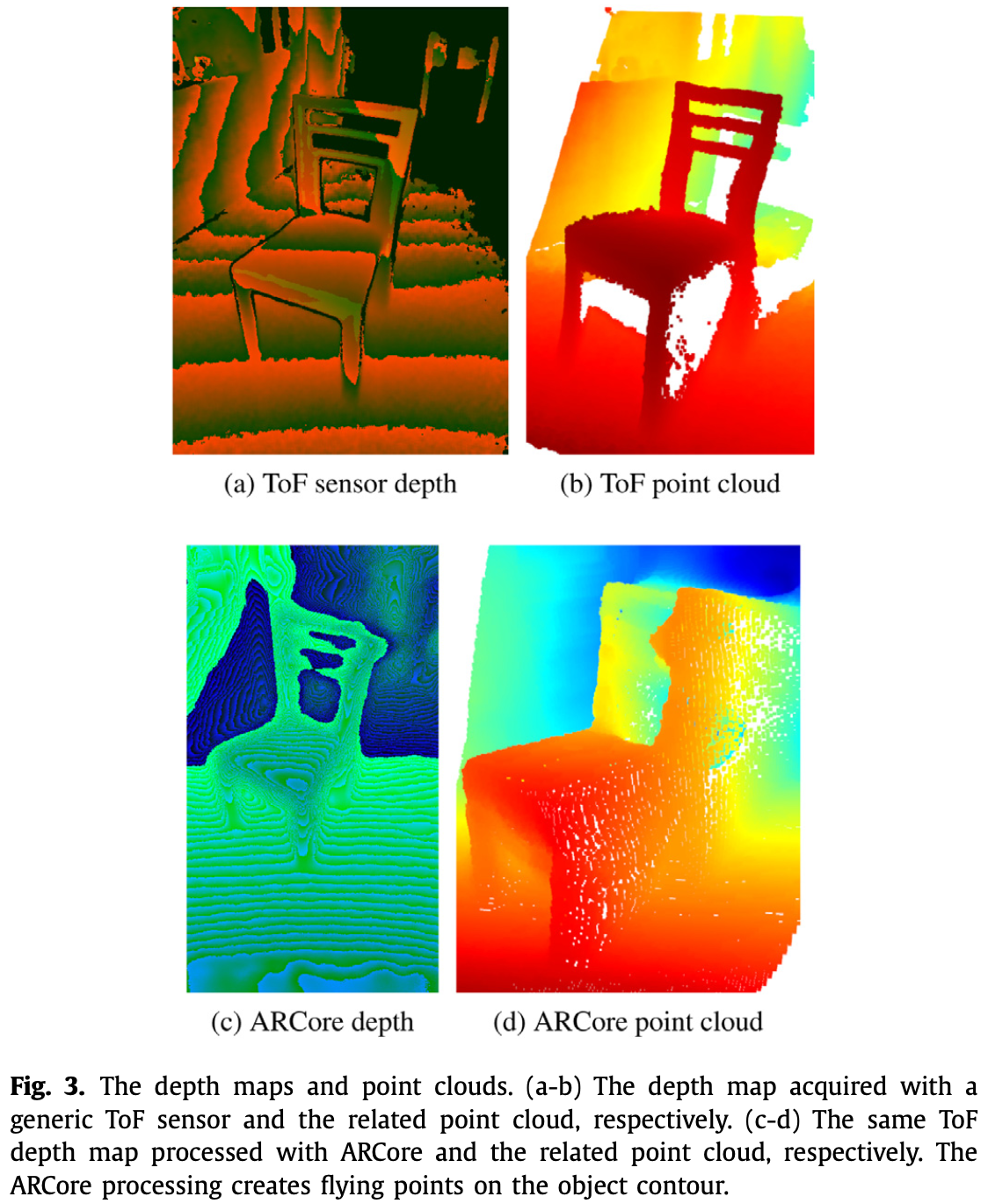
对于这样的物体,使用 RANSAC 分割点云,仅检测水平平面。然后,考虑检测出的平面上的点,计算 3D bounding box。此操作返回物体的大小和质心位置,其中(质心)垂直轴的值表示物体的高度。
当物体由存在空洞的部分组成时(如椅子)ARCore smoothing 过程产生作用于 3D bounding box 大小的 flying points。因此系统采用如下方法进行改进:
- 首先在深度图上创建深度不连续的掩码,以删除大部分 outliers:将类似于 [4] 中的自动 Canny edge detection algorithm 于深度图的灰度版本,该深度图经过标准化以增强深度变化。
- 然后,使用两种形态变化,dilation 和 closing。
如 Fig.4,Canny edge 的内核随着物体中心到手机距离的变化而变化。

生成的二进制掩码用于去除集中在深度不连续点云中的 outliers。RANSAC 算法在第二步检测物体的水平面,第三步应用 statistical outlier removal algorithm 在被平面分割的点云上,去除前一步剩下的离群值。整个过程如 Fig.5 所示。
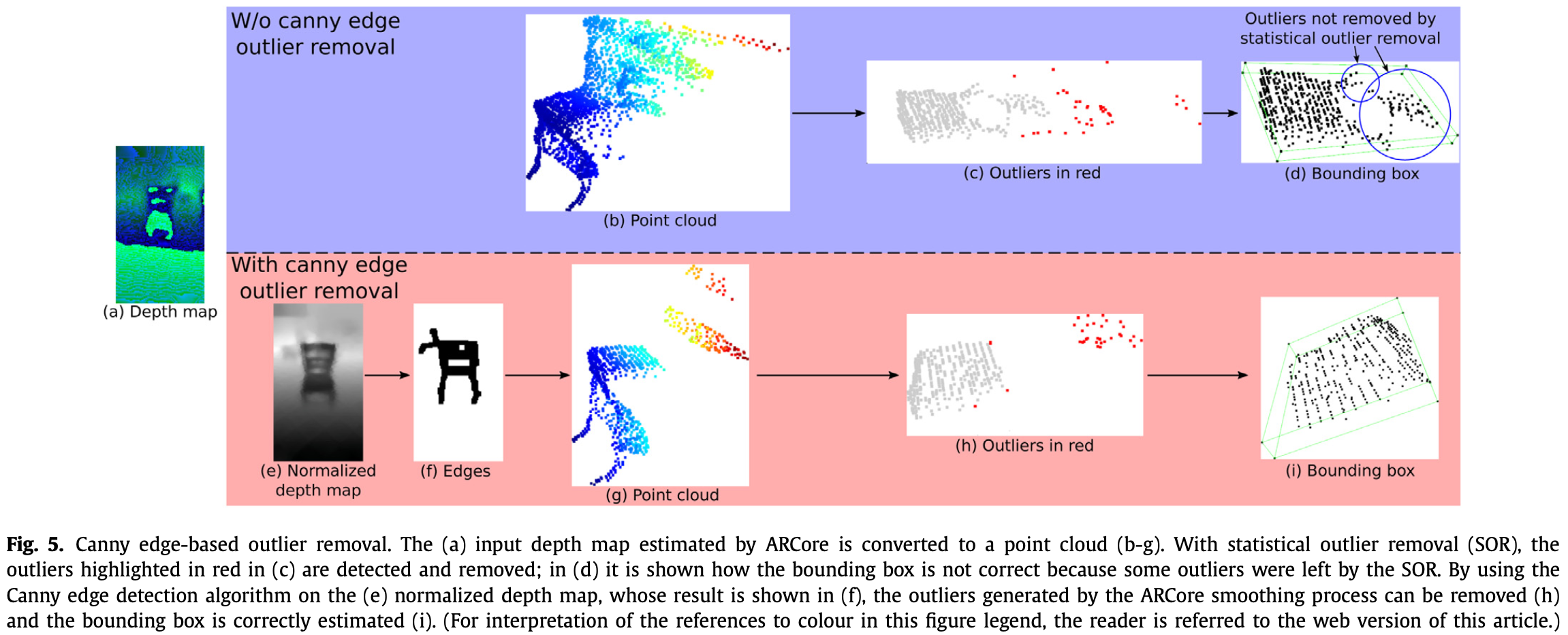
系统计算 RANSAC 找到的平面的 3D bounding box,得到物体的大小和质心,从而得到物体的高度。物体的整体高度通过找到分段点云数据的最高点来确定。
另一方面,该系统对橱柜、梳妆台和床头柜的处理不同:
- 分割网络并不总是预测正确的标签;
- 床头柜表面上的物体可能会在点云数据上产生伪像,RANSAC 算法无法检测到水平面;
- 摄像机可能无法框出橱柜的顶面,RANSAC 算法在这种情况下也无法找到平面。
对于这类物体,系统会找到分割点云的最高点,假设这是顶面的高度,然后通过移动垂直轴上的点来创建一个人工水平面。利用 Open3D 提供的面向三维的 bounding box 估计算法,得到物体的大小和质心的二维位置。
2.3 3D Model Retrieval
执行 3D 模型检索有不同的方法,本研究使用了 A VGG-19 [5] CNN,与 LFD[6] 等其他方法相比,提供了更好的细粒度 3D 模型检索。
ShapeNetCore 数据集[7] 中的一个 3D 模型子集是从 12 个视点进行提取,然后使用 ImageNet 上预训练的 VGG-19 CNN 提取特征。这些特征被计算和存储。通过计算提取的目标物体的特征与同一类别的 3D 模型渲染图的特征之间的欧氏距离来确定最相似的物体。
为减少图像噪声,系统使用第二阶段生成的二进制掩码从 snapshot 中提取查询物体,然后进行模糊操作以软化边界,最后进行裁剪去除大部分背景和其他元素。如图6所示为一个3D模型检索示例。

2.4 Object Pose Estimation
系统预测物体绕垂直轴的旋转。目前已有 DL 方法从单一 RGB 图像中解决目标姿态估计问题,但许多方法都要求神经网络必须针对被估计的特定目标进行训练。
因此,本文系统使用了 Pose From Shape[8],根据已知视点预测 RGB 图像中物体的视点。Pose From Shape 使用在 ShapeNet Core(ShapeNet 的子集,如 Fig.7)上训练的模型。

在 ShapNet Core 中,使用 Blender 从不同的视角提取并渲染所考虑类别的 3D 模型。
RGB snapshot 的背景会影响预测的准确性,因此系统使用上一阶段获得的物体分割的图像。
由于系统已经从上一步中检索了 3D 物体,它将与该对象相关的渲染集合和物体的分割照片提供给神经网络。
Pose From Shape 网络的输出是摄像机的视点,由方位角、俯仰角和面内旋转的欧拉角组成。系统只考虑用于表示物理对象的 3D 模型的方位。
2.5 Scene Reconstruction and AR Visualization
对于每个 snapshot,系统生成三个 CSV 文件,分别包含:
- 物体的位置和大小;
- 物体的垂直旋转;
- 手机的旋转。
同时,用于整个重建系统的地面高度 被存在另一个名为 Floor 的 CSV 文件中。地面高度是与 的最小值相差小于 4cm(观测得到)或更少的高度平均值:
利用 Unity3D 开发一个 APP,将重构的场景可视化。3D 模型取自 ShapeNet Core 数据集。对 3D 模型进行预处理,得到与系统预估结果一致的真实尺寸和质心位置。APP 解析所有 CSV 文件,选择 3D 模型并计算旋转、缩放和位置。

为了定性评估重建的准确性,所有的 3D 模型也通过一个移动 AR APP 可视化。用户可以在场景中自由移动,以验证 3D 模型是否正确地与真实物体重叠。由于几乎每一帧都估计了密集深度图,因此可以检查 3D 模型是否正确地叠加在物理对象上(Fig.8)。
3 Experimental Validation
- 数据集:使用一个包含一些不同形状的物体一共 500 张 snapshot 的数据集,这些物体按类划分并且其 snapshot 来自于不同的视点。
- 误差:
- scaling error:对于每个 snapshot,计算 GT 和物体的预测大小的 RMSE。然后,所有 RMSE 的平均值作为 scaling error。
- position error:物体中心点的误差。
- vertical rotation error:如 Fig.9。

- 实验结果:
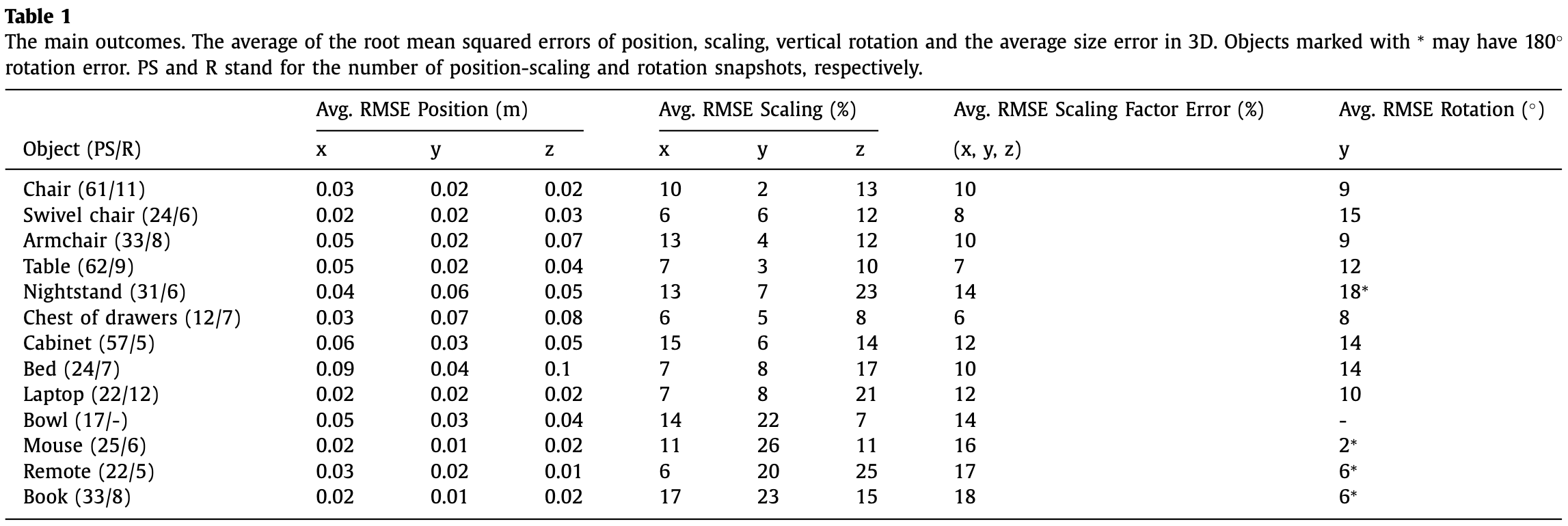
参考
- [1] Du R, Turner E, Dzitsiuk M, Prasso L, Duarte I, Dourgarian J, Afonso J, Pascoal J, Gladstone J, Cruces N, Izadi S, Kowdle A, Tsotsos K, Kim D. DepthLab: Real-Time 3D Interaction With Depth Maps for Mobile Augmented Reality. In: Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology. ACM; 2020.
- [2] Lambert J, Liu Z, Sener O, Hays J, Koltun V. MSeg: A composite dataset for multi-domain semantic segmentation. In: Computer Vision and Pattern Recog- nition (CVPR); 2020.
- [3] Zhou Q, Park J, Koltun V. Open3d: a modern library for 3d data processing. CoRR 2018;abs/1801.09847. http://arxiv.org/abs/1801.09847.
- [4] Canny J. A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell 1986;PAMI-8(6):679–98. doi:10.1109/TPAMI.1986.4767851.
- [5] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations; 2015.
- [6] Chen D-Y, Tian X-P, Shen Y-T, Ouhyoung M. On visual similarity based 3D model retrieval. Comput Graphics Forum 2003. doi:10.1111/1467-8659.00669.
- [7] Chang AX, Funkhouser TA, Guibas LJ, Hanrahan P, Huang Q, Li Z, Savarese S, Savva M, Song S, Su H, Xiao J, Yi L, Yu F. Shapenet: an information-rich 3d model repository. CoRR 2015;abs/1512.03012. http://arxiv.org/abs/1512.03012.
- [8] Xiao Y, Qiu X, Langlois P, Aubry M, Marlet R. Pose from shape: Deep pose esti- mation for arbitrary 3D objects. In: British Machine Vision Conference (BMVC); 2019.