YOLO-SLAM
对论文 YOLO-SLAM: A semantic SLAM system towards dynamic environment with geometric constraint (Neural Computing and Application 2022) 的阅读整理。
论文情况
- 标题:YOLO-SLAM: A semantic SLAM system towards dynamic environment with geometric constraint
- 作者:Wenxin Wu, Liang Guo, Hongli Gao, Zhichao You, Yuekai Liu, Zhiqiang Chen
- 期刊:Neural Computing and Application 2022
- 源码:未开源
1 Introduction
为有效地识别动态特征点,既利用深度学习在场景理解中的优势,又利用特征点内在的几何深度信息。这两个部分的设计可以帮助 SLAM 系统从语义和几何两个层面感知环境,获得对环境的高层次理解。
主要贡献:
- 在 SLAM 系统中设计并构建了轻量级的 Darknet19-YOLOv3 目标检测网络,该网络能够生成用于定位动态目标的必要语义信息。
- 为了有效地区分动态特征点和动态物体所在区域,提出了一种新的几何约束方法。
- 基于 ORB-SLAM2 成功构建了语义视觉 SLAM 系统 YOLO-SLAM,能够有效提高系统在动态环境下的精度和鲁棒性。
2 Proposed Method
2.1 Framework of YOLO-SLAM
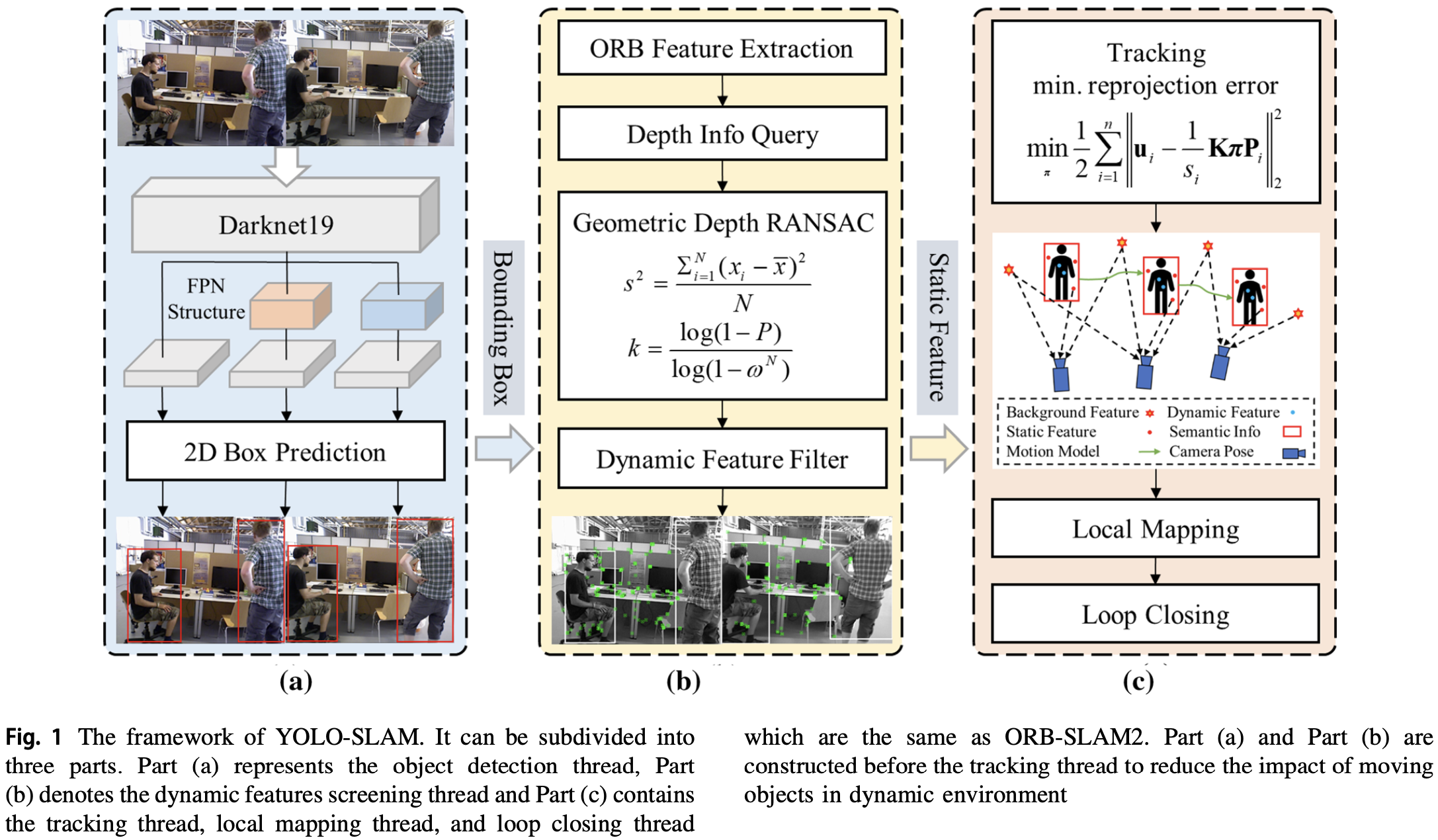
- 使用 ORB-SLAM2,其包含三个线程:跟踪、局部建图、回环检测。
- ORB-SLAM2 作为 YOLO-SLAM 的基础。
YOLO-SLAM:
- 在 ORB-SLAM2 上增加目标检测线程和动态特征筛选线程:
- 对象检测线程建立在轻量级 YOLOv3 之上,提供来自动态对象的语义信息。
- 动态特征筛选线程利用几何深度信息区分动态特征点。
- 目标检测线程通过生成 bounding box 来识别动态物体。
- 在每帧图像上提取 ORB 特征点。
- 动态特征筛选线程接收边界框信息生成纯静态特征点,利用几何深度 RANSAC 方法将特征点分为动态特征点和静态特征点。
- 局部建图线程和回环检测线程利用静态特征来构建稀疏地图和检测回环约束。
动态特征移除过程:
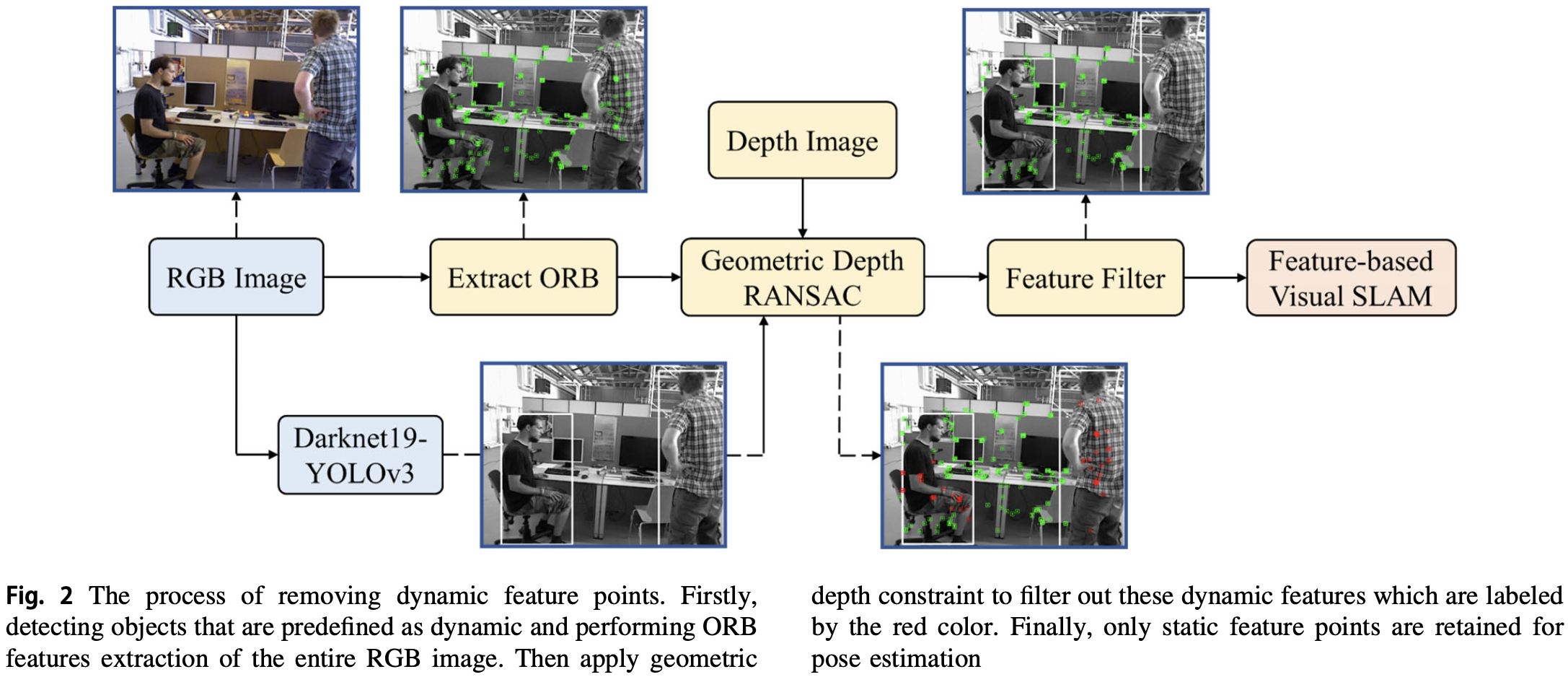
2.2 Lightweight Object Detection
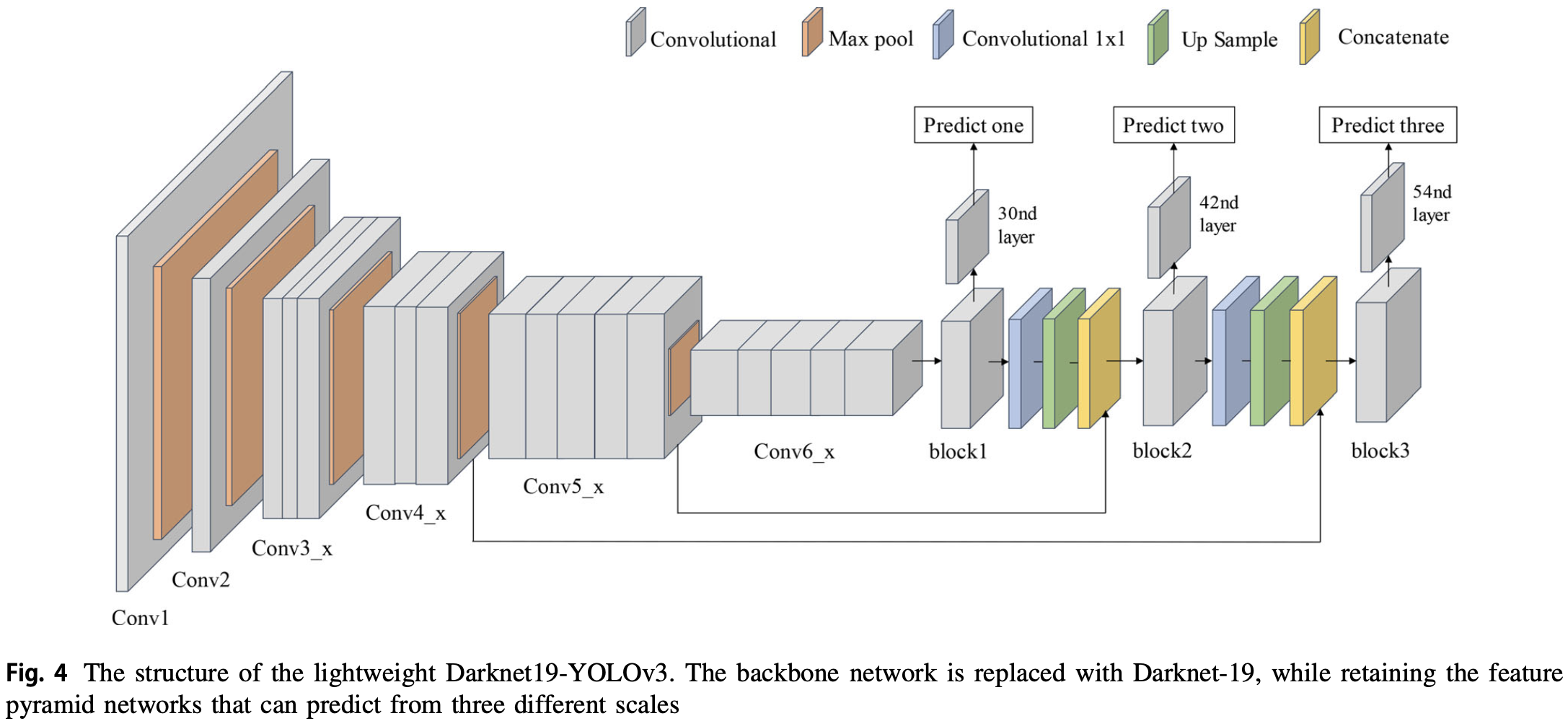
考虑准确和速度,使用 YOLOv3,并将 YOLOv3 的 backbone 从 Darknet-53 改为 Darknet-19。修改后的 YOLOv3 结构如图,网络在 PASCAL VOC 2007 和 2012 上进行训练:
Darknet19-YOLOv3 的超参数为:
- batch = 64, subdivision = 16, width = 416, height = 416, channels = 3, momentum = 0.9, decay = 0.0005, saturation = 1.5, exposure = 1.5, hue = 0.1, learning rate = 0.001, max batches = 10000, epoch = 100。
损失函数为:
-
表示 bounding box 的坐标预测误差:
其中 为误差权重, 为网格的数量, 为每个网格中 bounding box 的数量, 为第 个 box 是否为正确的 box 预测, 为预测值, 为 GT。
-
为 IOU 预测误差:
用于减弱不包含物体的网格的影响, 为预测的置信度, 为置信度 GT。
-
为分类预测误差:
其中 为类别编号, 为预测的物体类别概率, 为概率 GT。
Darknet19-YOLOv3 工作流程:
- 输入 的图像。
- Darknet19-YOLOv3 在三个不同尺度下进行检测,并将特征图分别降采样 为 32、16 和 8。
- 在 3 个卷积层上应用 检测核得到最终的检测结果。检测核的形状为 , 表示一个网格能检测的 bounding box 的数量,4 为四个 bounding box 参数,1 为网格中是否存在物体, 被物体类别的总数。实验中 ,只考虑识别物体是否为人。
- 当物体检测分类为人时,提取在人上的特征点将会被视为 outliers 并被剔除。
2.3 Dynamic Features Screening
经过目标检测模块后,可以获取语义信息,并返回目标所属的类别和四个坐标,形成一个 bounding box。一些方法选择直接删除所有落在 bounding box 中的特征点。这是一种剔除动态点的简单方法,但也剔除了许多包含在边界框中的静态点:
- 静态特征点的减少会削弱特征匹配的约束,限制求解更精确的解。当检测框占当前帧的三分之二以上时,则只有少量的特征点用于跟踪,从而可能导致 SLAM 系统失效。
利用深度图像中的几何深度信息解决这个问题。由 RGB-D 相机获取的部分深度图像如 Fig.5 所示。在深度图像中,通过深度差可以明显区分物体的轮廓。借助深度图,通过 depth-RANSAC 方法分离出边界框中剩余的静态特征。

方法基于 3 个假设:
- 人是最可能移动的物体,占据了边界框的大部分。
- 出现在人体上的特征点深度值相差不大。
- 在边界框中,人与周围物体的深度差异明显。
基于上述三个假设筛选 outliers 的 depth-RANSAC 算法可如 Algorithm I。

-
在边界框内寻找特征点并将其存储在一个集合中;
-
进入循环,直到迭代次数不少于预先设定的次数,在循环中:
-
任意选择边界框中提取的两个特征点,并计算这两个点之间的方差作为 depth-RANSAC 模型。
-
遍历所有剩余的点,找到方差在正确范围内的点,得到一组特征点。
-
当遍历结束时,选择包含最多内部点的集合,用于最终识别为出现在动态对象轮廓内的 outliers。
-
-
从整个提取的特征点中筛选出 outliers,将剩余的点视为静止点。
depth-RANSAC 模型描述为:
其中, 表示方差, 为每次选择用于估计模型的的点数量, 为被选择的点的深度, 为深度的平均值。
算法中 (在 TUM 数据集上),每个 bounding box 在迭代时的迭代次数 为:
- 假设所有点中 inliers 的比例为:
每次用 个点计算 RANSAC 模型,至少选到一个 outlier 的概率为 ,迭代 次则为 。设 为 次迭代中,每次所选择的点均为 inliers 的概率,则有:
最终:
为先验值, 为预设值。 在实验中自适应,初始为无穷大,然后在每次迭代中不断更新。
3 Experimental Results
-
数据集:TUM RGB-D
-
特征点提取对比:

- 绝对轨迹误差 ATE 和相对位姿误差 RPE 的对比:
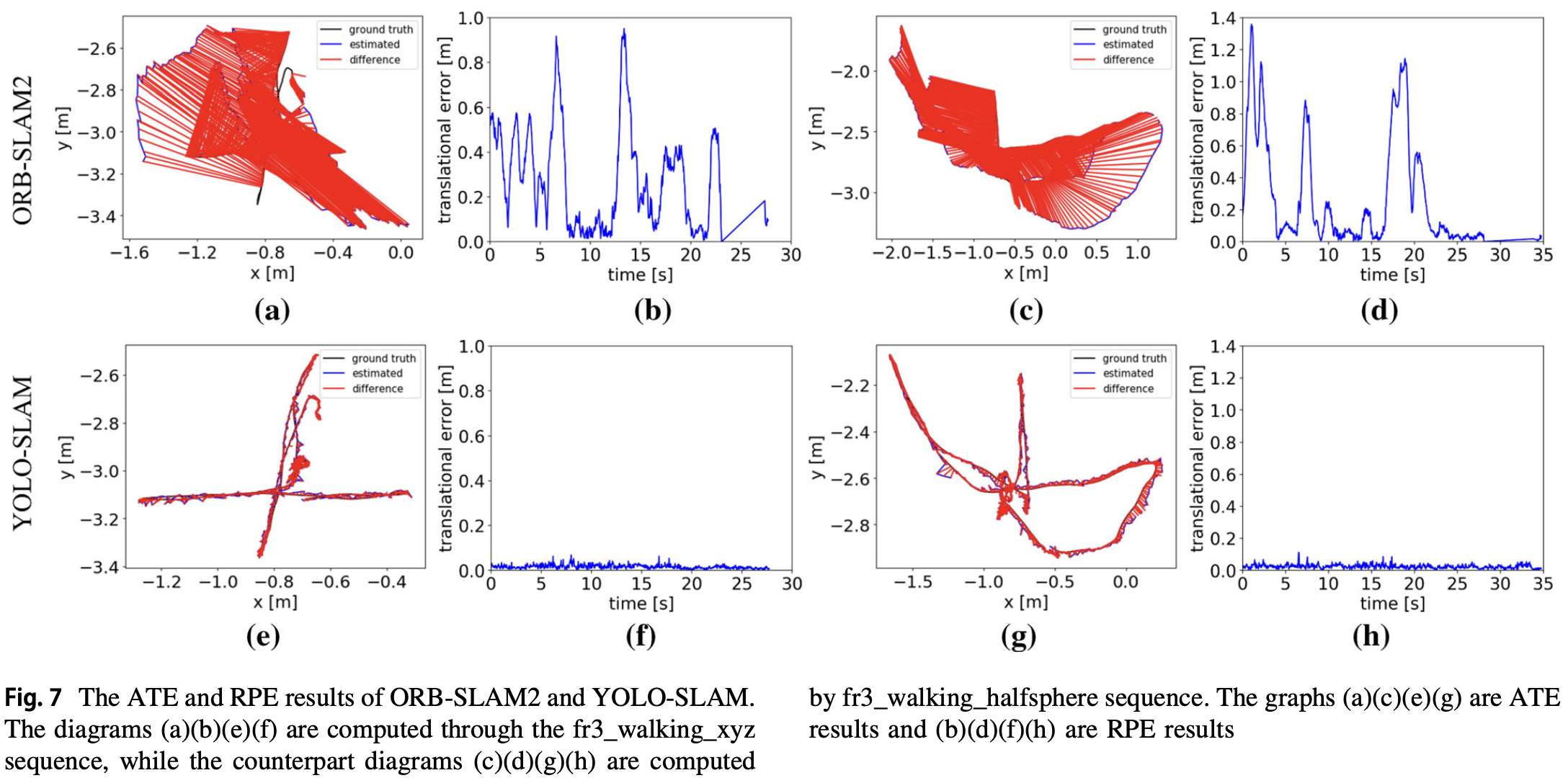
- 消融实验:
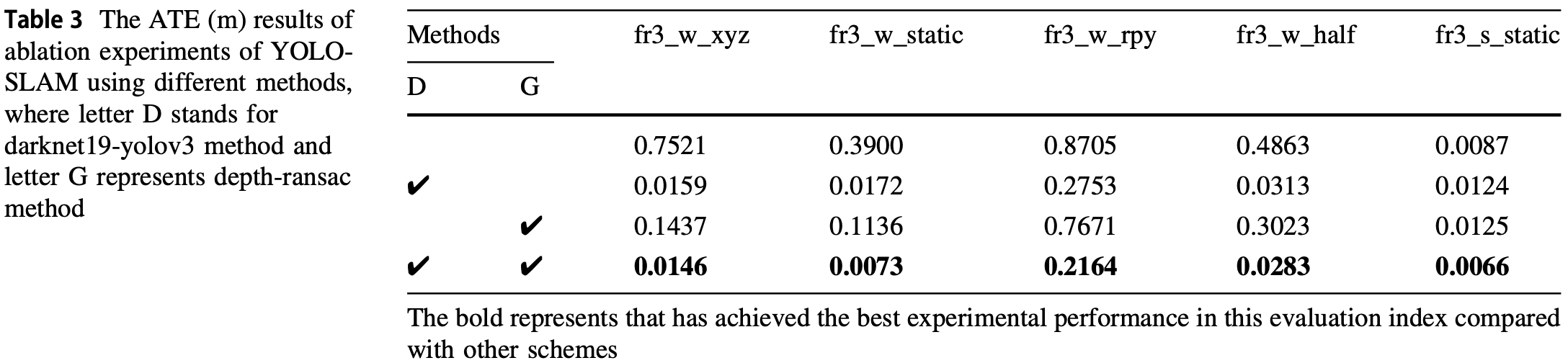
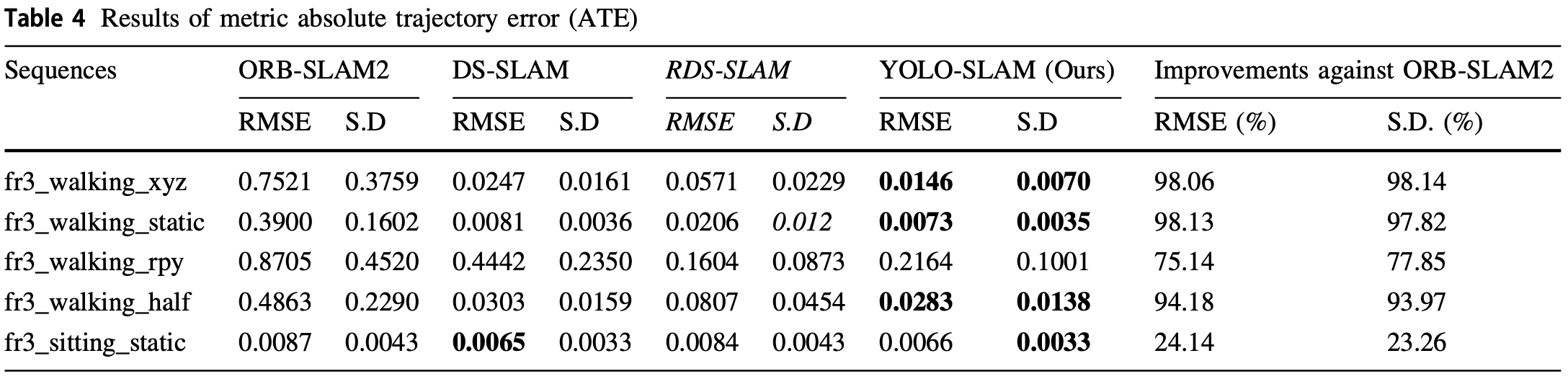
- 不同模型间的对比(ATE = RMSE):
- 旋转/平移漂移: