传统 CNN 中,训练完成后所有 kernal 参数则固定。对于任意的输入,所有的 kernal 都对他们同等对待。所以为了提高模型 capacity,大多数方法堆叠卷积层(深度)或者增加卷积层的 channel 数(宽度),这种做法一定程度上可以提升模型能力,但会降低计算效率。
为了压缩模型,在增加模型 capacity 的同时不会增加太多参数和计算量,动态卷积在训练结束后,kernal 不再是一个定值,而是一个由 input 决定的变量。因此 kernal 相当于一个以 input 为自变量的函数。这种做法变相增加了模型 capacity,而模型参数和计算量是非常小的。
动态卷积
1 简介
随着模型参数的不断增加,计算成本也越来越高,对于一些对 latency 有较高要求的任务,显然是一种挑战。在传统 CNN 中,训练完成后所有 kernal 参数则固定。对于任意的输入,所有的 kernal 都对他们同等对待。所以为了提高模型 capacity,大多数方法堆叠卷积层(深度)或者增加卷积层的 channel 数(宽度),这种做法一定程度上可以提升模型能力,但会降低计算效率。
为了压缩模型,在增加模型 capacity 的同时不会增加太多参数和计算量,动态卷积在训练结束后,kernal 不再是一个定值,而是一个由 input 决定的变量。因此 kernal 相当于一个以 input 为自变量的函数。这种做法变相增加了模型 capacity,而模型参数和计算量是非常小的。
2 动态感知机
通过感知机模型引出动态卷积,设感知机模型如下,W,b,g 分别表示权重、偏置和激活函数:
y=g(WTx+b)
动态感知机的定义如下,动态感知机模型如 y 式,聚合权重(W~(x))和聚合偏置(b~(x))通过 W 式和 b 式中多个权重和偏置加权求和得到。需要满足的条件约束是权重系数和为 1,这也说明了权重系数不固定,随着输入数据的变化而变化。
y=g(W~T(x)x+b~(x))W~(x)=k=1∑Kπk(x)W~kb~(x)=k=1∑Kπk(x)b~ks.t. 0≤πk(x)≤1, k=1∑Kπk(x)=1
式中 πk 表示第 k 个线性函数 W~kTx+b~k 的 attention 权重,这个权重在输入 x 不同的情况下是不同的。因此在给定 input 的情况下,动态感知器代表了该 input 的最佳线性函数组合。
3 动态卷积
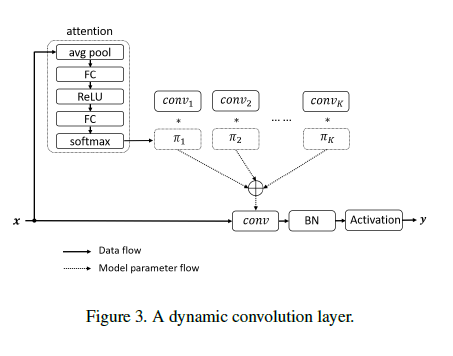
图-1 动态卷积
动态卷积有 K 个卷积核,这些卷积核有相同的大小,相同的输入和输出通道。
3.1 注意力
动态卷积采用压缩激励操作来计算卷积核注意力 πk(x)。首先,全局信息通过平均池化来进行压缩。然后,使用两个全连接层(之间采用 ReLU 激活函数)和 softmax 函数,来生成 K 个卷积核的归一化注意力权重。其中,第一个全连接层用于降维。
3.2 聚合卷积核
由于核的尺寸较小,聚合卷积核的计算效率较高。同时,在 softmax 中采用了以恶很大的温度来平衡注意力:
πk=∑jexp(zj/γ)exp(zk/γ)
zk 是注意力分支中的第二个全连接层的输出,γ 是温度,原始 softmax 中 γ=1。采用退火技巧,在前 10 次迭代中将 γ 从 30 变成 1,可以进一步提高准确度。
4 代码实现样例(PyTorch)
4.1 attention 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
| class Attention2d(nn.Module):
def __init__(self, in_planes, K):
super(Attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_planes, K, 1)
self.fc2 = nn.Conv2d(K, K, 1)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return F.softmax(x, 1)
|
4.2 Dynamic Convolution 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| class DynamicConvolution2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0,
dilation=1, groups=1, bias=True, K=4):
super(DynamicConvolution2d, self).__init__()
assert in_planes % groups == 0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = Attention2d(in_planes, K)
self.weight = nn.Parameter(torch.Tensor(K, out_planes,
in_planes//groups, kernel_size,
kernel_size),
requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.Tensor(K, out_planes))
else:
self.bias = None
def forward(self, x):
softmax_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width)
weight = self.weight.view(self.K, -1)
aggregate_weight = torch.mm(sofrmax_attention,
weight).view(self.out_planes, -1,
self.kernel_size,
self.kernel_size)
if self.bias is not None:
aggregate_bias = torch.mm(softmax_attention, slef.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggreagate_bias,
stride=self.stride, padding=self.padding,
dilation=self.dilation,
groups=self.groups*batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None,
stride=self.stride, padding=self.padding,
dilation=self.dilation,
groups=self.groups*batch_size)
output = output.view(batch_size, self.out_planes,
output.size(-2), output.size(-1))
return output
|
参考
源码