RPN
本文是关于 Region Proposal Network 相关网络资料的整理。
1 RoI Pooling
RoI Pooling 是目标检测任务中的常见手段,作用是将一系列大小不同的 RoI 投影至特征图上,然后通过池化操作将它们处理为一致大小,从而方便后面的网络层进行处理,同时起到了加速计算的作用。
1.1 RoI(Region of Interest)
机器视觉、图像处理中,从被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出需要处理的区域,称为感兴趣区域(Region of Interest),RoI。
在 Halcon、OpenCV、MatLab 等机器视觉软件上常用到各种算子(Operator)和函数来求得感兴趣区域 RoI,并进行图像的下一步处理。 在图像处理领域,RoI 是从图像中选择的一个图像区域,这个区域是图像分析所关注的重点。圈定该区域以便进行进一步处理。使用 RoI 圈定需要读取的目标,可以减少处理时间,增加精度。
1.2 RoI Pooling(将不同尺寸变为相同尺寸)
RoI Pooling 的步骤:
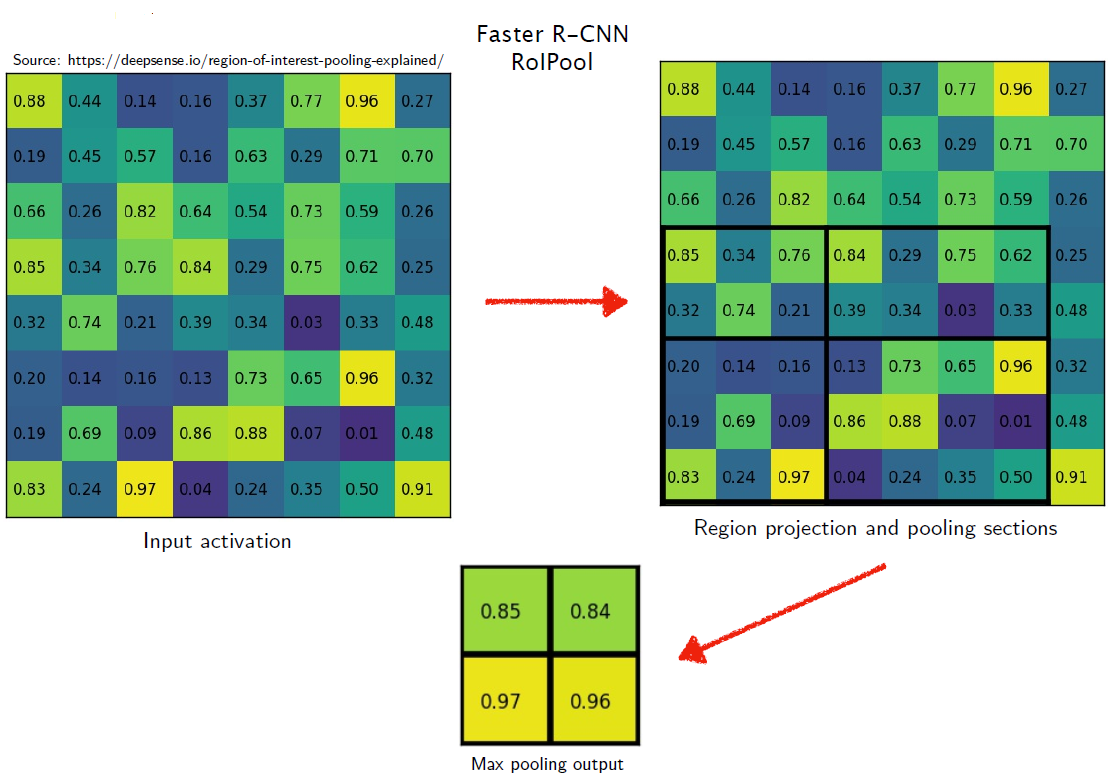
- RoI 的尺寸通常对应输入图像,特征图是输入图像经过一系列卷积层后的输出,因此,首先将 RoI 映射到特征图上的对应区域位置;
- 最终需要将尺寸不一的 RoI 变为固定的 大小,于是将 RoI 平均划分为 个区域;
- 取每个划分而来的区域的最大像素值,即对每个区域做 max pooling 操作,作为每个区域的“代表”,这样每个 RoI 经过操作后就变为 大小。
-
例:
如图-1,假设输入图像经过一系列卷积层下采样 32 倍后输出的特征图大小为 ,现有一 RoI 的左上角和右下角坐标( 形式)分别为 和 ,映射至特征图上后坐标变为 和 ,由于像素点是离散的,因此向下取整后最终坐标为 和 ,这里产生了第一次量化误差。
假设最终需要将 RoI 变为固定的 大小。将 RoI 平均划分为 个区域,每个区域长宽分别为 和 即 3.5 和 2.5,同样,由于像素点是离散的,因此有些区域的长取 3,另一些取 4,而有些区域的宽取 2,另一些取 3,这里产生了第二次量化误差。
1.3 RoI Align(没有量化误差)
1.3.1 RoI Align
RoI Align 是在 Mask R-CNN 中提出来的,基本流程和 RoI Pooling 一致,但是没有量化误差。结合例子说明:
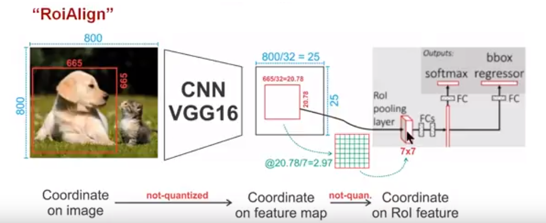
输入图像分辨率为 ,其中一个 RoI 大小为 ,输入图像经过 VGG16 下采样 32 倍后输出分辨率为 的特征图。
-
将 RoI 映射至特征图上,大小为 即 ,注意这里没有进行取整;
-
最终需要将 RoI 输出为 大小,因此将 大小的 RoI 均分为 个区域,每个区域大小为 ,注意这里也没有取整;
-
RoI Align 需要设置一个超参,代表每个区域的采样点数,即每个区域取几个点来计算“代表”这个区域的值,通常为 4;
-
对每个划分后的区域长宽各划分为一半,“十字交叉”变为 4 等份,取每份中心点位置作为其“代表”,中心点位置的像素值利用双线性插值计算获得,这样就得到 4 个中心点像素值,采样点数为 4 即为此意;
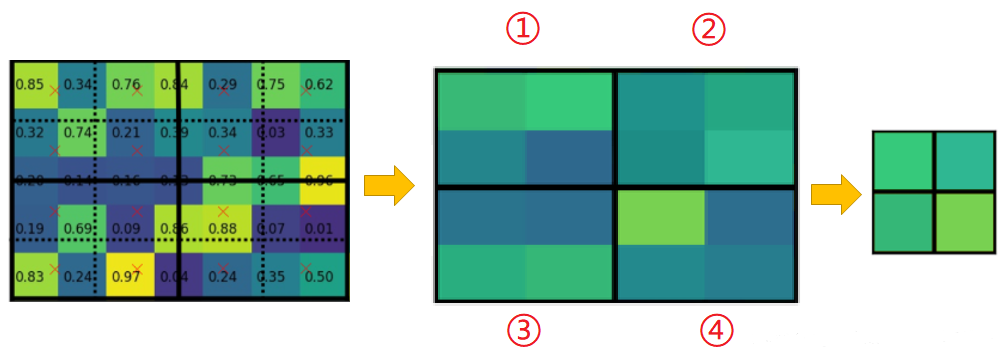
- 每个 的区域都有 4 个中心点像素值,取 4 个中心点像素值中的最大值作为其“代表”,这样 个区域就产生 个值,最终将 RoI 变为 大小。
1.3.2 双线性插值
核心思想是在两个方向分别进行一次线性插值。
-
先确定变量
- 四个像素点:
- 像素点坐标:
- 像素值:
- 横向插值插入的两个点为 ,坐标为
- 纵向插值插入的一个点为 ,坐标为
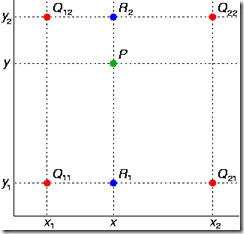 图-4 双线性插值
图-4 双线性插值 -
插值的目的
图像扩展,由已知的像素点的值来计算出来原本不存在的像素点。
-
插值的方法
- 先横向插,再纵向插
- 先纵向插,再横向插
-
计算过程
-
计算横向插值,由 和 计算 的过程:
交叉相乘并化简,得到:
-
同理,由 和 计算 :
-
结合 和 在 方向插值得到 :
化简得:
将 和 带入 得到:
-
1.4 Precise RoI Pooling(无需超参数)
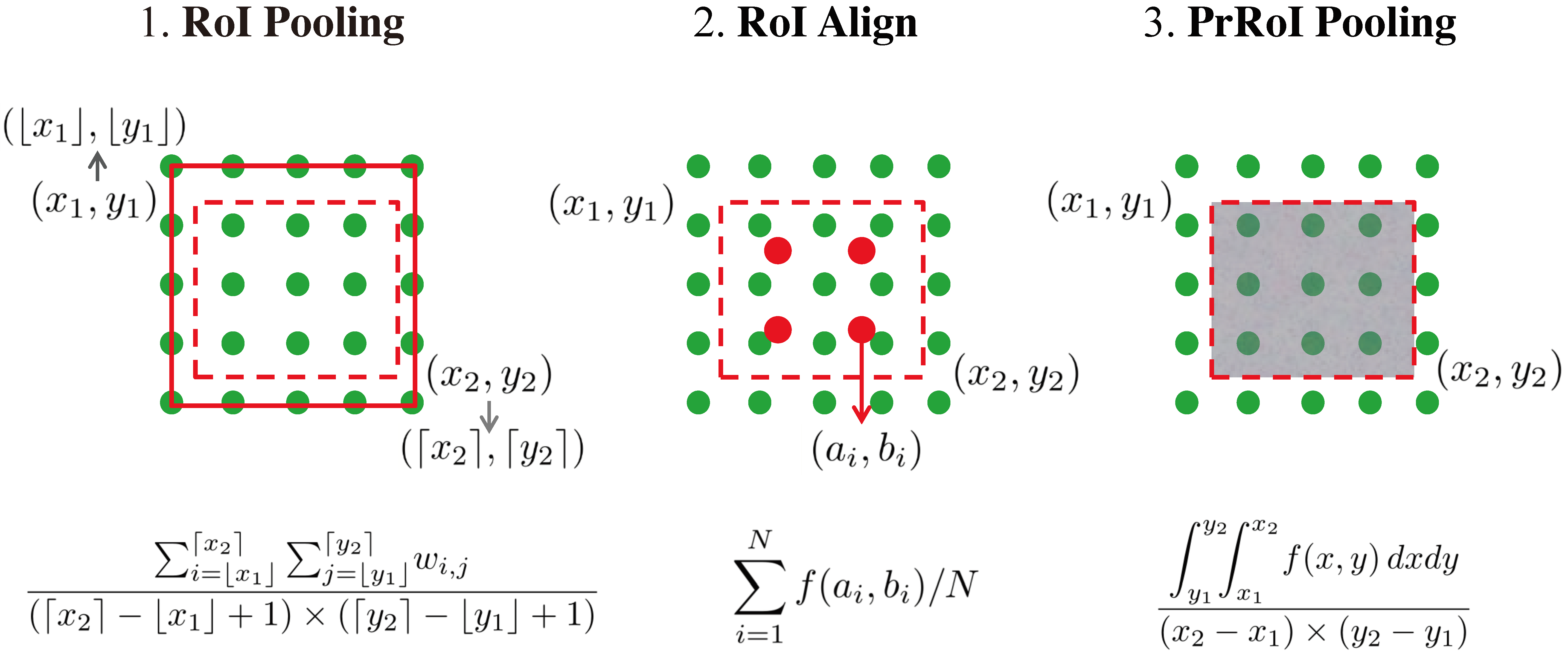
RoI Align 虽然没有量化损失,但是却需要设置超参,对于不同大小的特征图和 RoI 而言这个超参的取值难以自适应,Precise RoI Pooling 可以解决这一问题。
Precise RoI Pooling 和 RoI Align 类似,将 RoI 映射到特征图以及划分区域时都没有量化操作,不同的是,Precise RoI Pooling 没有再次划分子区域,而是对每个区域计算积分后取均值来“代表”每个区域,因而不需要进行采样。
由上述公式可知,区域内的每点在反向传播中对梯度都是有贡献的,而对 RoI Align 和 RoI Pooling 来说,只有区域内最大值那点才对梯度有贡献,相当于“浪费”了大部分的点。
2 RPN(Region Proposal Network)
RPN 用于生成候选区域(Region Proposal),其输入为 backbone(VGG16,ResNet 等)的输出 feature maps。Faster R-CNN 用 RPN 产生检测狂,提升检测框的生成速度。
2.1 RPN 的组成
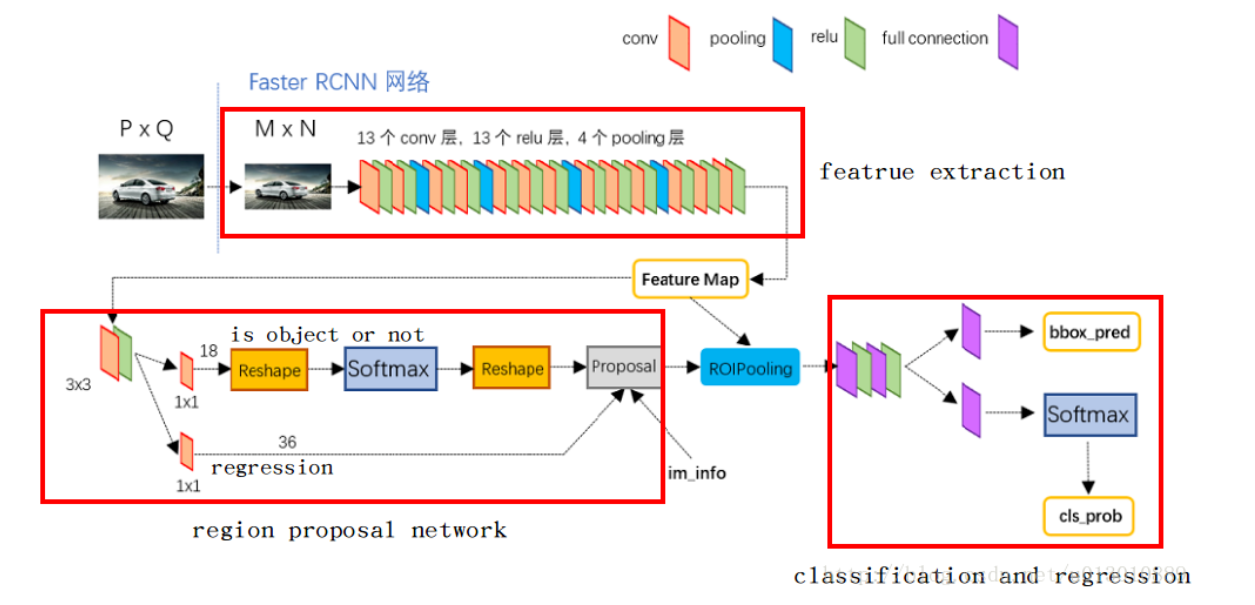
RPN 包括以下部分:
-
生成 anchor boxes
-
anchor box 可以用 4 个值 表示,可以表示 anchor box 的左上角和右下角的坐标;anchor box 也可以表示为 ,其中 表示 anchor box 的某个点(左上角、中心点等)的坐标, 表示 anchor box 的大小。anchor box 的具有 个固定的宽高比。
-
遍历 feature map,为每一个点都配 个 anchor box 作为初始的检测框,后面再通过 bounding box regression 进行检测框位置的修正。设 feature map 的尺寸为 ,那么总共有 个 anchor box。
-
-
判断每个 anchor box 为 foreground(包含物体)或background(背景)
-
边界框回归(bounding box regression)对 anchor box 进行微调,使得 positive anchor 和真实框(ground truth box)更加接近
2.2 对 anchor boxes 的处理
得到 anchor boxes 后,需要完成以下任务:
- 二分类问题检测 anchor box 中是否包含物体,分类为 foreground 和 background。
- 如果 anchor box 包含物体,那么需要通过回归进行调整,使 anchor box 与 ground truth 更加接近。
即:设 backbone 输出 feature map 的尺寸为 ,设置 个 anchor boxes,则 RPN 的卷积网络处理后得到输出:
- 大小为 的 positive/negative Softmax 分类矩阵,记为 。
- 大小为 的 bounding box regression 坐标偏移矩阵,即对原始 anchor box 做的修改和缩放 ,记为 。
对于回归操作:
-
给定 anchor 和 ground truth ,找到一组变换 使得 ,较简单的思路为:
- 先平移:
- 再缩放:
- 先平移:
2.3 RPN 中的 proposal
proposal 的输入为:
- softmax 的分类矩阵
- bounding box regression 坐标矩阵
- :设输入图片尺寸为 ,再 Faster R-CNN 预处理中,会 reshape 为 ,则 ,即保存了缩放信息。
proposal 的输出为:
- :RPN 产生的 RoI
- :表示 RoI 中包含物体的概率
后续处理中,设定阈值 ,如果某个 RoI 满足 ,则再判定其中物体的类别,否则忽略。
3 Source Code
-
Faster R-CNN 源码地址:https://github.com/rbgirshick/py-faster-rcnn
-
Faster R-CNN 中 RPN 部分源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276#========= RPN ============
layer {
name: "rpn_conv/3x3"
type: "Convolution"
bottom: "conv5"
top: "rpn/output"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 256
kernel_size: 3 pad: 1 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_relu/3x3"
type: "ReLU"
bottom: "rpn/output"
top: "rpn/output"
}
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
bottom: "rpn_cls_score"
top: "rpn_cls_score_reshape"
name: "rpn_cls_score_reshape"
type: "Reshape"
reshape_param { shape { dim: 0 dim: 2 dim: -1 dim: 0 } }
}
layer {
name: 'rpn-data'
type: 'Python'
bottom: 'rpn_cls_score'
bottom: 'gt_boxes'
bottom: 'im_info'
bottom: 'data'
top: 'rpn_labels'
top: 'rpn_bbox_targets'
top: 'rpn_bbox_inside_weights'
top: 'rpn_bbox_outside_weights'
python_param {
module: 'rpn.anchor_target_layer'
layer: 'AnchorTargetLayer'
param_str: "'feat_stride': 16"
}
}
layer {
name: "rpn_loss_cls"
type: "SoftmaxWithLoss"
bottom: "rpn_cls_score_reshape"
bottom: "rpn_labels"
propagate_down: 1
propagate_down: 0
top: "rpn_cls_loss"
loss_weight: 1
loss_param {
ignore_label: -1
normalize: true
}
}
layer {
name: "rpn_loss_bbox"
type: "SmoothL1Loss"
bottom: "rpn_bbox_pred"
bottom: "rpn_bbox_targets"
bottom: 'rpn_bbox_inside_weights'
bottom: 'rpn_bbox_outside_weights'
top: "rpn_loss_bbox"
loss_weight: 1
smooth_l1_loss_param { sigma: 3.0 }
}
#========= RoI Proposal ============
layer {
name: "rpn_cls_prob"
type: "Softmax"
bottom: "rpn_cls_score_reshape"
top: "rpn_cls_prob"
}
layer {
name: 'rpn_cls_prob_reshape'
type: 'Reshape'
bottom: 'rpn_cls_prob'
top: 'rpn_cls_prob_reshape'
reshape_param { shape { dim: 0 dim: 18 dim: -1 dim: 0 } }
}
layer {
name: 'proposal'
type: 'Python'
bottom: 'rpn_cls_prob_reshape'
bottom: 'rpn_bbox_pred'
bottom: 'im_info'
top: 'rpn_rois'
# top: 'rpn_scores'
python_param {
module: 'rpn.proposal_layer'
layer: 'ProposalLayer'
param_str: "'feat_stride': 16"
}
}
layer {
name: 'roi-data'
type: 'Python'
bottom: 'rpn_rois'
bottom: 'gt_boxes'
top: 'rois'
top: 'labels'
top: 'bbox_targets'
top: 'bbox_inside_weights'
top: 'bbox_outside_weights'
python_param {
module: 'rpn.proposal_target_layer'
layer: 'ProposalTargetLayer'
param_str: "'num_classes': 21"
}
}
#========= RCNN ============
layer {
name: "roi_pool_conv5"
type: "ROIPooling"
bottom: "conv5"
bottom: "rois"
top: "roi_pool_conv5"
roi_pooling_param {
pooled_w: 6
pooled_h: 6
spatial_scale: 0.0625 # 1/16
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "roi_pool_conv5"
top: "fc6"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
scale_train: false
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
scale_train: false
}
}
layer {
name: "cls_score"
type: "InnerProduct"
bottom: "fc7"
top: "cls_score"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
inner_product_param {
num_output: 21
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "bbox_pred"
type: "InnerProduct"
bottom: "fc7"
top: "bbox_pred"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
inner_product_param {
num_output: 84
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "loss_cls"
type: "SoftmaxWithLoss"
bottom: "cls_score"
bottom: "labels"
propagate_down: 1
propagate_down: 0
top: "cls_loss"
loss_weight: 1
loss_param {
ignore_label: -1
normalize: true
}
}
layer {
name: "loss_bbox"
type: "SmoothL1Loss"
bottom: "bbox_pred"
bottom: "bbox_targets"
bottom: 'bbox_inside_weights'
bottom: 'bbox_outside_weights'
top: "bbox_loss"
loss_weight: 1
}
参考
- https://zhuanlan.zhihu.com/p/106192020
- https://blog.csdn.net/JNingWei/article/details/78847696
- https://blog.csdn.net/qq_44554428/article/details/125001468
- https://zhuanlan.zhihu.com/p/59186710
- https://zhuanlan.zhihu.com/p/328441287#:~:text=RoI Pooling 是目标检测任务中的常见手段,最早在 Faster,R-CNN 中提出,作用是将一系列大小不同的 RoI 投影至特征图上,然后通过池化操作将它们处理为一致大小,从而方便后面的网络层进行处理(历史原因,以前的网络结构中最后几层往往是全连接层,因此需要固定的输入尺寸),同时起到了加速计算的作用。
- https://blog.csdn.net/qq_42902997/article/details/105087407
- https://codeantenna.com/a/FX94FZ0Pn8